


While really just a PR rebrand of software testing, evals are what allow us to demonstrably prove that a modification to an agent has produced a meaningful change. The mental friction, however, that comes with applying an understanding of testing to agents can be somewhat difficult. After spending a lot of time trying and implementing different ways, I thought it would be useful to clearly outline my definition and approach for quick reference here.
As mentioned, evals mirror general software testing practices, so we will parallel our definitions to pre-existing terms and show the application back towards agent engineering. Specifically, we’ll discuss four kinds of evals:
- Unit Test Evals - Given a pre-set state, evaluate the next step an agent takes.
- Integration Test Evals - Given a pre-set state, evaluate the outcome the agent produces.
- Online Evals - Evaluate a metric of interest over a period of time.
- Benchmarks - A generalized evaluation of an agent’s capability.
Together, these four categories measure performance, surface limitations, ensure regression-free modifications, and provide a target for optimization. But before we define each one, we have to answer two necessary questions for context: 1) what is actually getting evaluated, and 2) how is it being measured.
What Gets Evaled
The standard method for logging what an agent is doing has materialized in the form of a trace. A trace captures information about the agent’s environment, inputs, outputs, and evolution of the state across its execution. In this sense, a trace encompasses a single invocation of an agent from start to finish. Within the trace are the individual runs, including LLM calls, function calls, middleware, and any other step that may have happened along its lifespan.
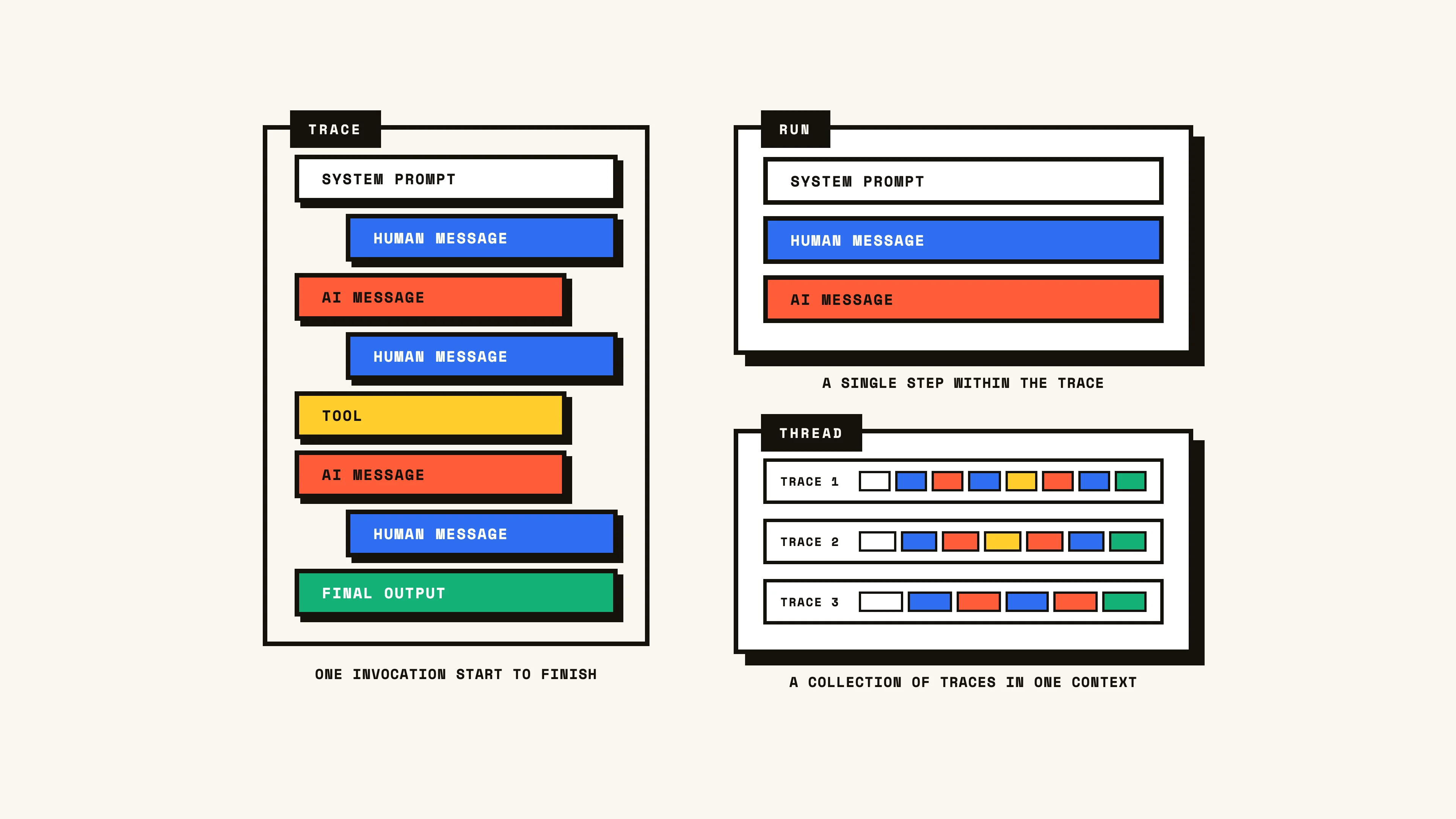
Note: In the hierarchy of agent observability, a thread sits above the trace representing a continuous collection of traces, often the result of subsequent invocations or turns within the same context. E.g. multiple instances of the same chat agent responding to a user across a conversation.
For the sake of simplicity, we’ll refer to the trace broadly and configure traces and runs accordingly to fit our various evals. Across all four, we are ultimately scoring one of two things: the step (did the right thing happen?) or the contents (is the output good?), applied at either the run or trace level.
How It is Measured
In considering the nature of a step vs contents, the approach to scoring follows a few norms. Steps are almost always measured in a deterministic way, similar to the assertions of traditional tests, given that there’s usually a right step to take that we compare against (e.g. an expected tool call).
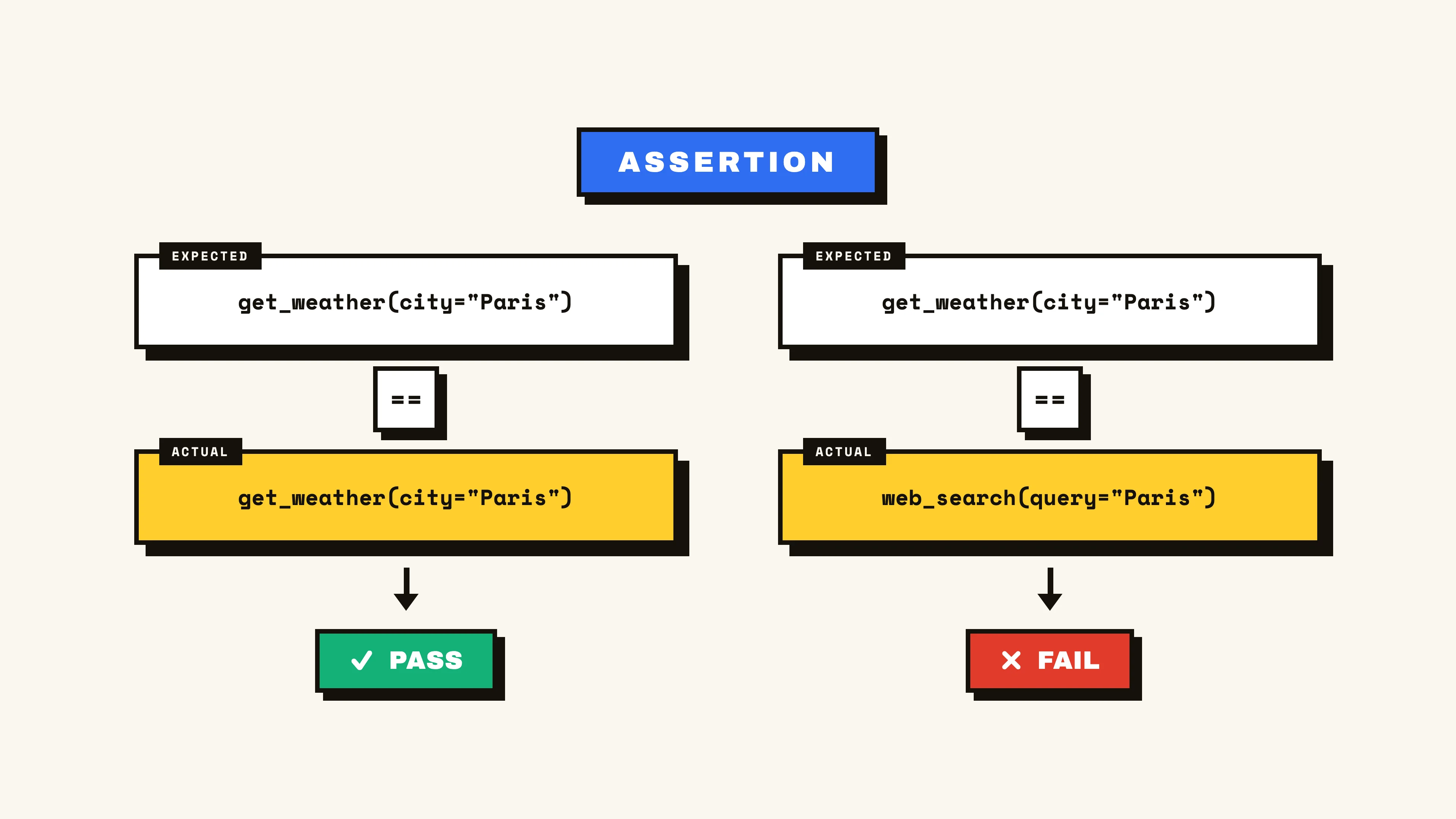
Measuring contents becomes more nuanced. We can still approach this deterministically via methods such as exact matches, regex comparisons, or other functions like F1 or ROUGE, but often the “quality” of contents is more subjective. This is where we introduce LLM-as-a-judge to subjectively score output contents against a written prompt. Implementation looks like describing the expected outcome, and relying on a language model’s text processing intelligence to make the decision as to whether the content matches your description.
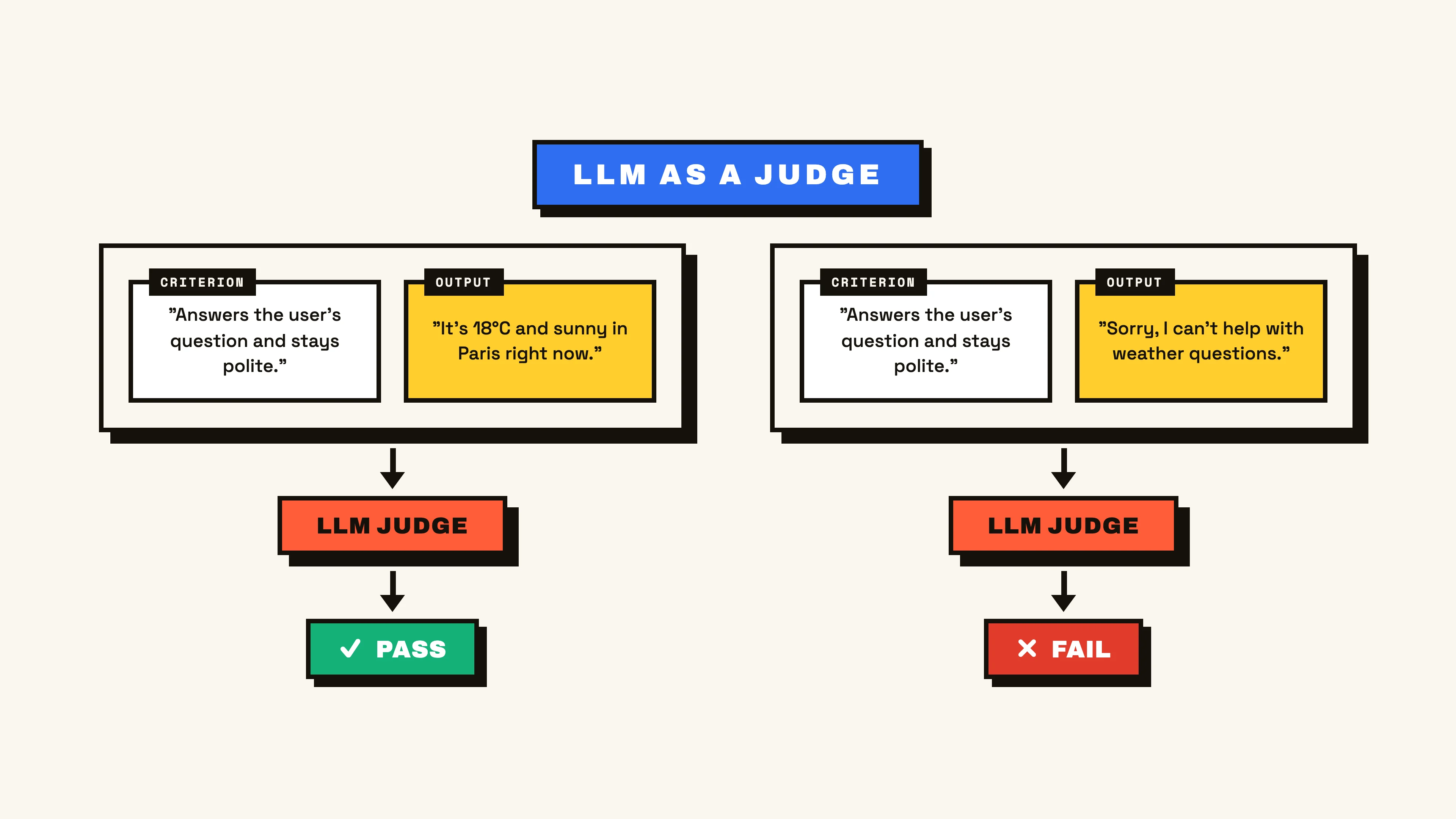
Note: A common pitfall with LLM-as-a-Judge implementations is having the LLM score on a scale. While it can be tempting to ask the model to judge contents 1-10 (often under the guise that you’ll get more granular insights), doing this correctly is difficult and often results in a skewed outcome. Keeping an LLM-as-a-judge’s score to a boolean pass/fail gives a clearer signal while being easier to align to expected scoring behavior.
These various scoring dimensions can also be combined into a rubric, where we take multiple ways a trace is being measured, apply a weighting to the different evals based on importance, and aggregate them into a final score called the reward. A reward can then be an easy overall tell of performance, given the underlying scores and evals are representative of your agent’s quality.
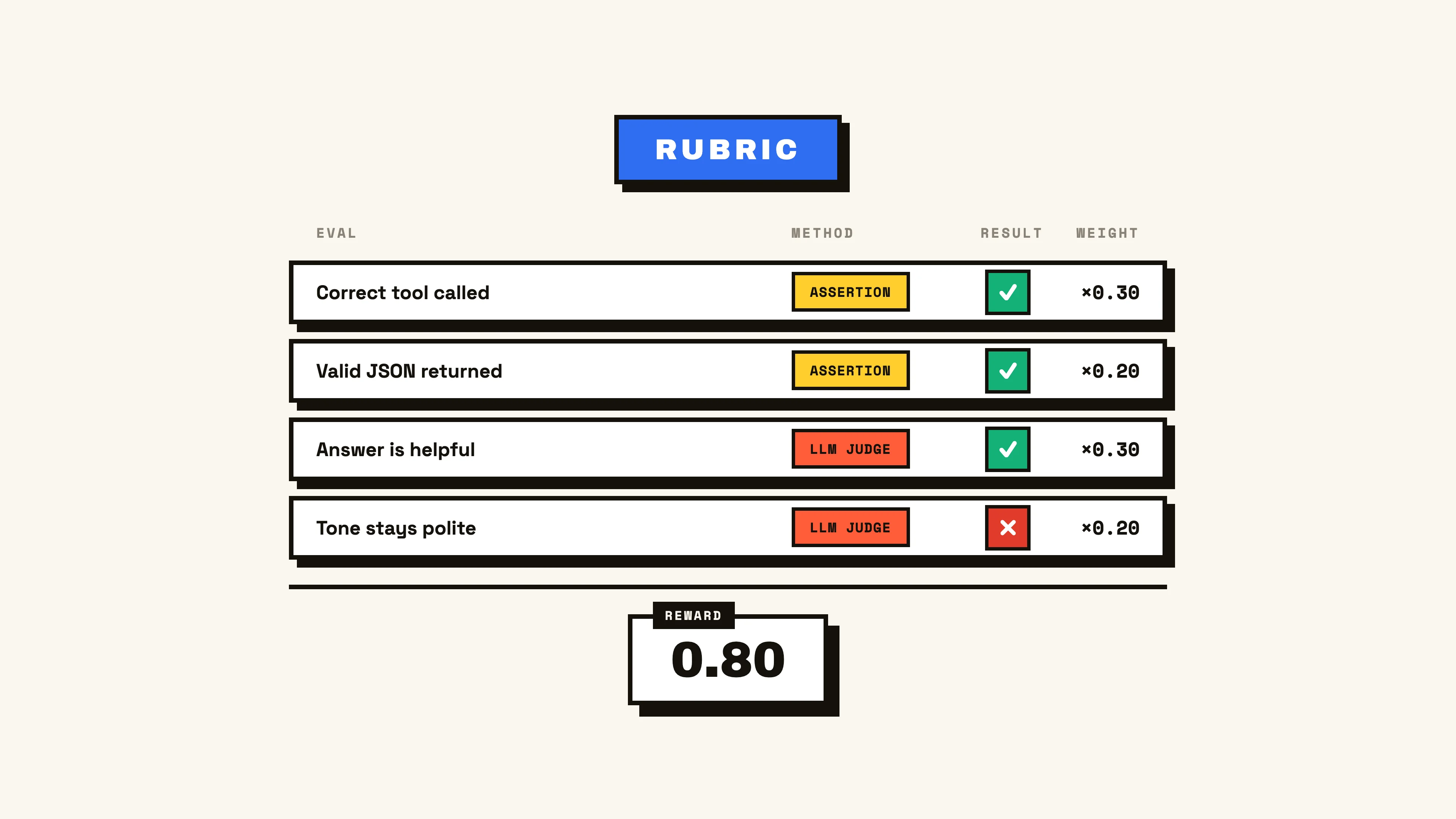
These various scoring methods become a lot more comprehensible when discussed in the context of a specific eval, so let’s get into the breakdown!
Unit Tests
Unit test agent evals, or what I like to call “behavioral unit tests”, assert that a certain behavior happens under various conditions. Specifically, we’re testing whether, given an environment and starting state, the action we expect happens next. Setup looks like taking all the prior messages and steps in a thread, recreating the surrounding environment (if applicable) that existed at that moment in time, and resuming the agent exactly as it would in a live scenario. We let it process for a turn, and then interrupt the run after the next step has been completed. We then compare that next step to our ground truth, either directly via a direct match assertion, or subjectively via an LLM-as-a-judge.
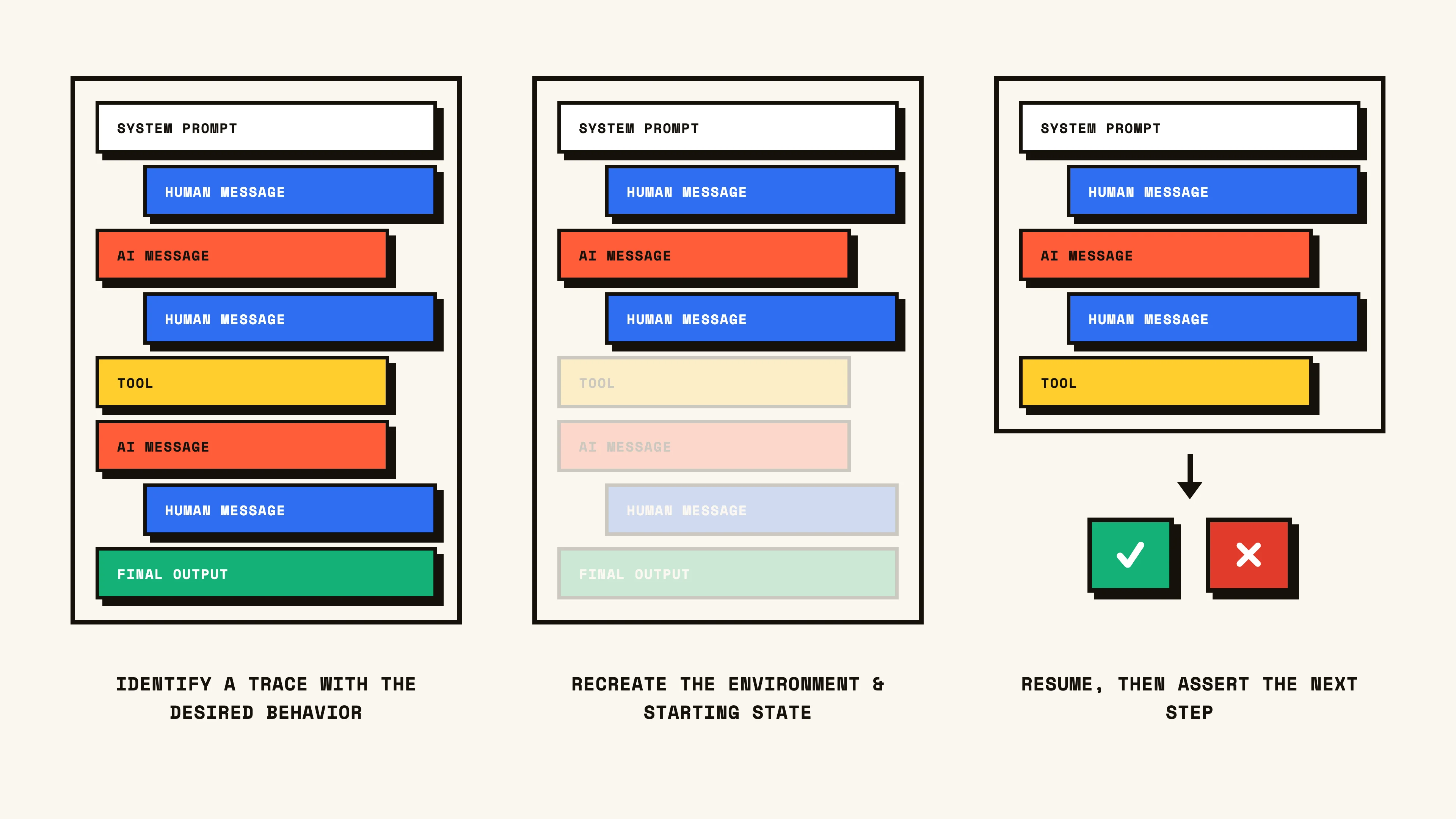
For example, consider the evaluation of an e-commerce customer service agent that has access to common customer service tools like process_return(), escalate_support(), lookup_user(), etc. We want to set up an eval that would measure its ability to process a user’s return. We expect that when a user provides an order ID and refund request that the first thing the agent will do is call the process_return(order_id=<int>, reason=<str>) tool, inputting the provided order ID and reason for return. We set up our behavioral unit test by reconstructing the message sequence (in this case just the user’s request message), and recreate our agent (often by importing it from its respective module). We pass the message sequence to the agent, allow it to generate a response, and then stop the execution.
We can then measure the generated response across various dimensions. We may:
- Assert that
process_return()was the next generated step - Assert that the
order_idmatched the input exactly - Judge the quality of the generated reason
So on, and so forth.
Behavioral unit tests are best used to cement intended behavior, and surface when a prompt change or update to the agent causes a regression in this behavior. The development loop becomes a cycle of writing evals for specific desired behavior that the agent has, and then running these evals when an update has been made to see if it is able to maintain those behaviors. As more capabilities are added, a respective behavioral unit test lands shortly after.
Integration Tests
Agent integration tests are much like behavioral unit tests, rather we shift our judgement solely to the output. In other words, we black box the actual process (individual steps) the agent takes to reach an outcome, and only evaluate the final result. Setup looks similar, but in this case we only care about mocking the starting state, environment, and initial inputs of the agent. Once all is kicked off, we let the agent operate until it resolves, and evaluate the final output. The scope of scoring widens as the final output of an agent can produce a variety of artifacts, ranging from a simple text response to a multi-step research report and everything in between.
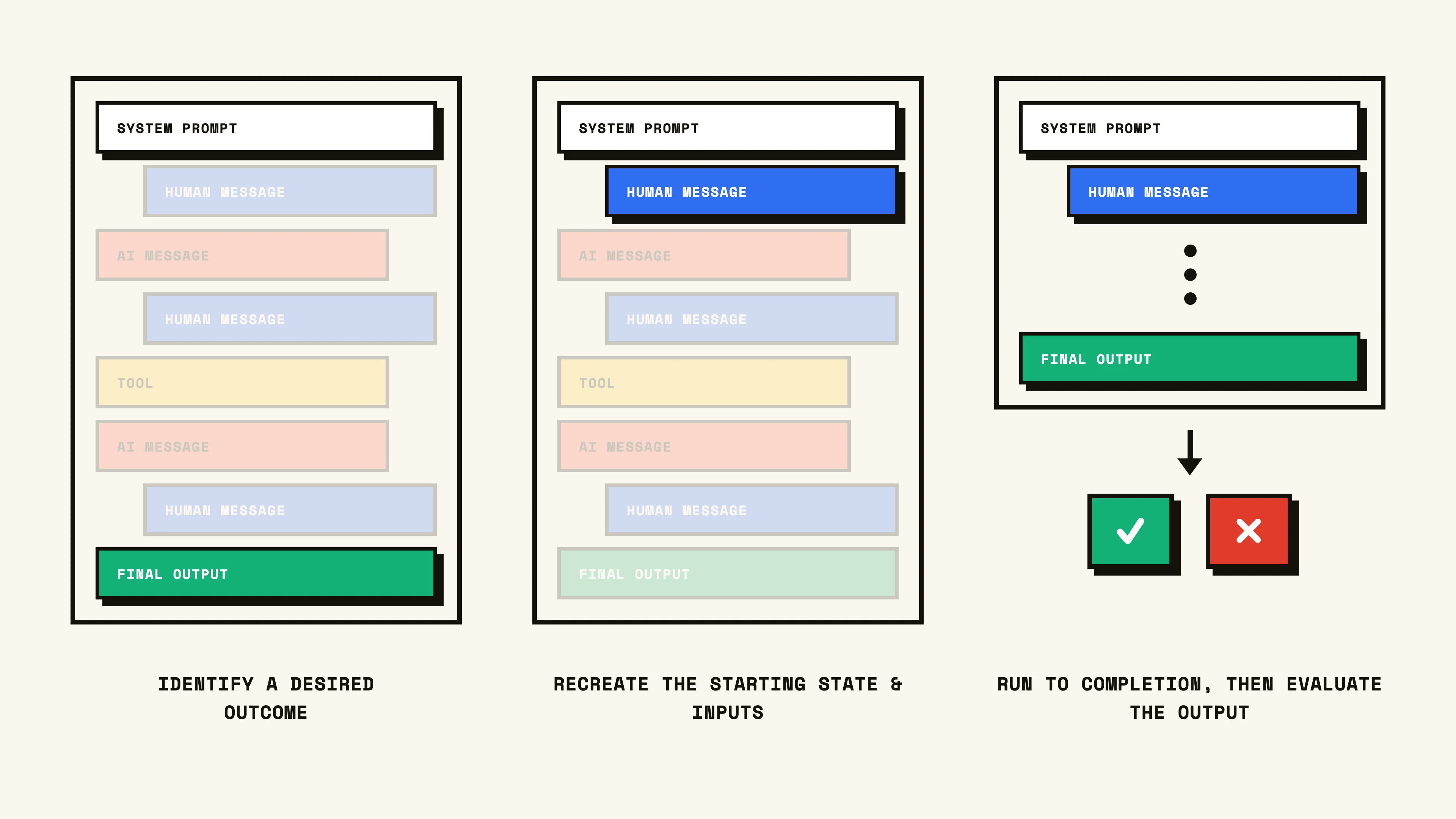
For example, consider a deep-research style agent that performs competitive market research, and relies on multiple sub agents and web search tools to provide a comprehensive report. We want to set up an eval that would measure the report it generates. We set up our agent integration test by reconstructing the environment and starting state (at this point just the system prompt and first human message), and inputting it into our agent. We allow the agent to operate fully, where it goes off and performs targeted research via web searches and sub agent investigations, and returns a generated report at the end.
We can then measure the generated report across various dimensions. We may:
- Assert that the report follows an expected structure
- Judge the quality of the generated contents
- Compare the generated report with an example of a quality report on the same topic
So on, and so forth.
As you can see, these tests are similar to our aforementioned unit tests, but instead of assessing how the agent arrived at a conclusion, we only care about the quality of the results. These can be, however, more token intensive to run as they involve a full invocation of the agent from start to finish. This style of integration test eval is generally used to measure an agent’s overall accuracy, precision, recall, F1, and other similar metrics as they relate to its purpose.
Note: I refer generally to subjective assessment as measuring “quality.” By quality I mean the degree of value/utility that an output provides to the end user of the agent. Naturally, this is an incredibly subjective measurement and should be personalized to your needs. Often this involves aligning an LLM-as-a-judge to a human’s annotated scoring and feedback.
Online Evals
Up until now, our two defined unit and integration test evals would be considered “offline evals,” in that they rely on a historical dataset that is evaluated outside of a live system. While great for repeated, controlled tests, it’s likely we want to also analyze our agent’s performance as it operates over a period of time. This is where online evals come in. Online evals operate under different circumstances from unit and integration tests, as they run against real interactions as they happen, rather than a fixed dataset. Due to their nature, they (often) have no ground truth to compare a step or output to either.
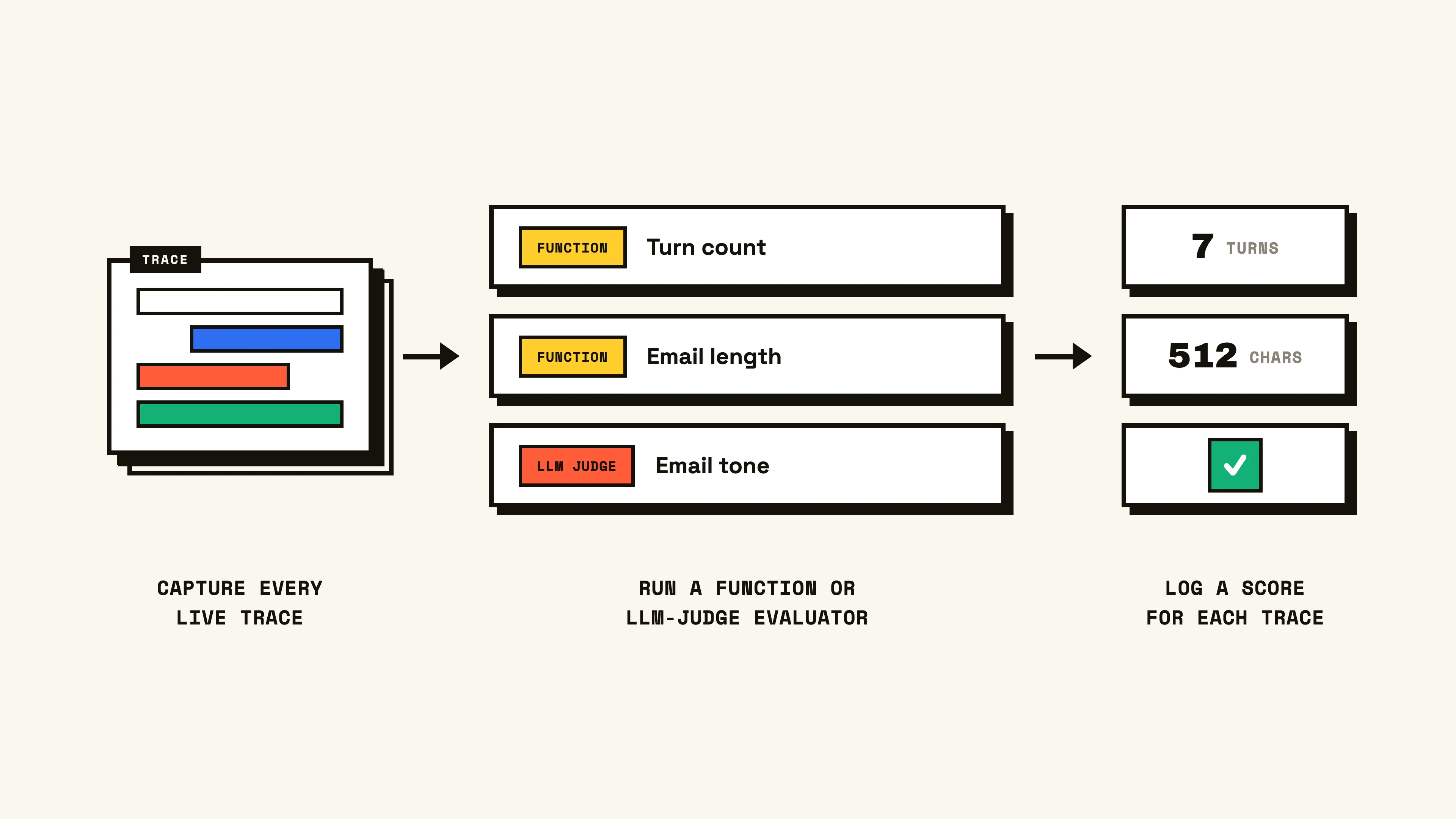
Online evals are more likened to general observability and monitoring (opposed to running experiments) and allow us to measure an agent’s live performance in production. Setup looks like taking each incoming agent trace and running a function (code) evaluator or an llm-as-a-judge evaluator against it. This logs a score for each trace that can then be displayed as a line chart over time, telling us how the metric has trended and alerting us if it reaches a certain threshold.
For example, consider a sales development agent that researches prospective accounts and sends an outreach email to a listed contact. In this scenario the agent has already been built, and is running in production today. Its traces are being logged to an agent observability platform (like LangSmith!), and we want to monitor the behavior and output trends from this agent. Specifically, we’re concerned with its turn count, verbosity, and email tone. To set up the three online evals, we would create:
- A function that counts the trace’s turn length
- A function that counts the generated email’s character length
- An LLM-as-a-judge that assesses whether or not an email’s tone is professional based on our expectations
We then run these evaluators and collect their datapoints as the agent operates and new traces are ingested, giving us an understanding of how turn-efficient, verbose, and professional it is being. We can set alerts for metric trends to notify us of abnormalities and outliers. Say a prompt update inadvertently caused the agent to become more terse- this would be surfaced as a downward trend in the generated email’s character length, compared against a standard range we expect it to be in.
Note: Given the volume of traces an agent can produce in production, online evals are typically run on a sample of traces. More important evals like policy or guardrail checks will run on a higher sample while more expensive evals, like llm-as-a-judge, may only measure a fraction.
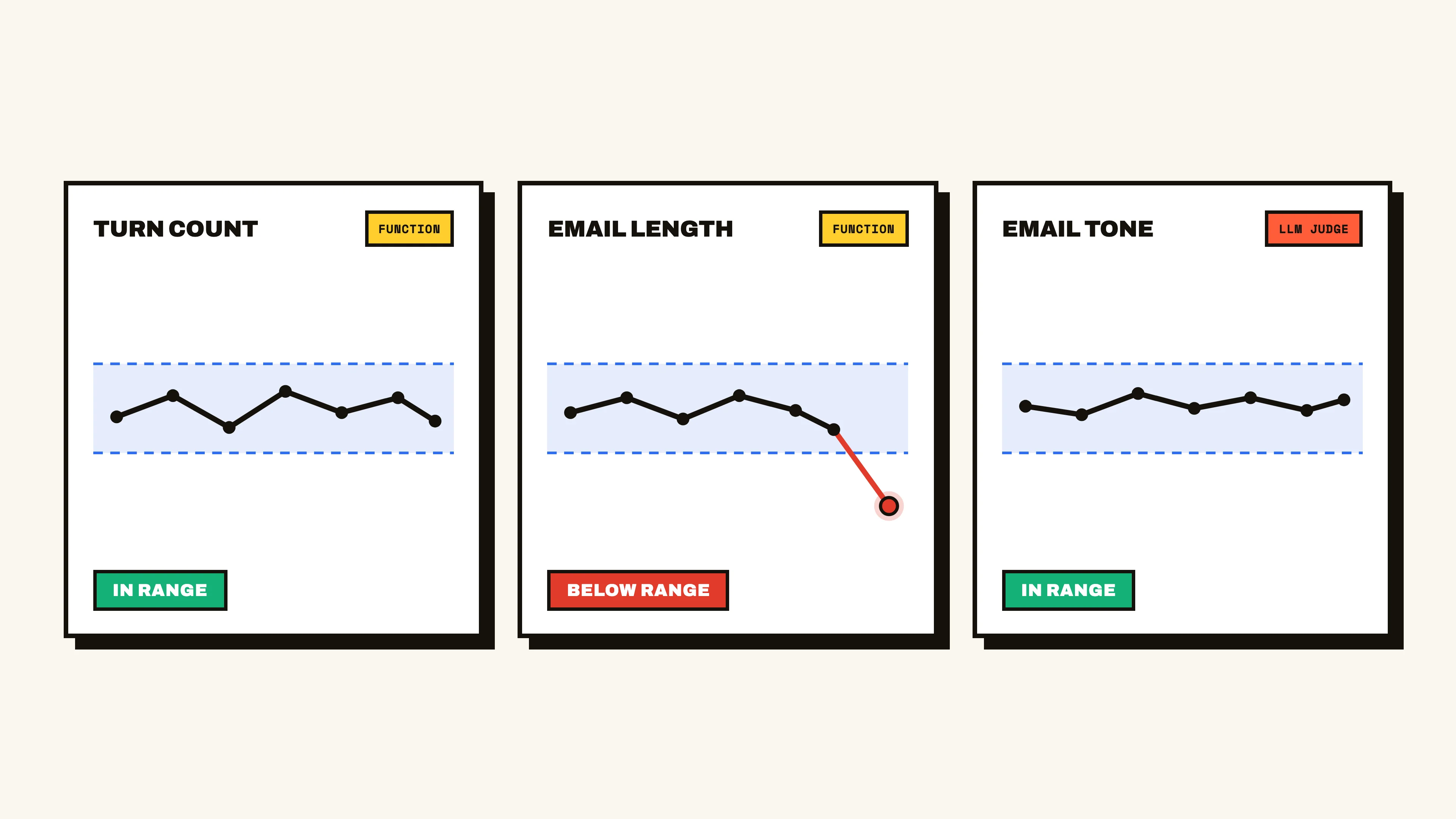
Online evals are incredibly useful for measuring trends, but can also be used to flag anomalous traces as they come in, isolate relevant sections for deeper inspection, and scale analysis of live agent behavior in ways that would be impossible to do manually.
Benchmarks
Our last three evals have been specific to measuring a single agent, but benchmarks diverge from this norm by decoupling the evaluation from the implementation. Instead, benchmarks intend to accurately measure performance for a specific capability in an agent-agnostic manner. Most notable of these agent benchmarks is SWE-bench, which measures an agent’s ability to resolve GitHub issues effectively. It’s made up of 2,249 tasks that consist of a codebase, GitHub issue, corresponding pull request, and a suite of tests that fail in the task’s starting state, but pass when the given PR is implemented.
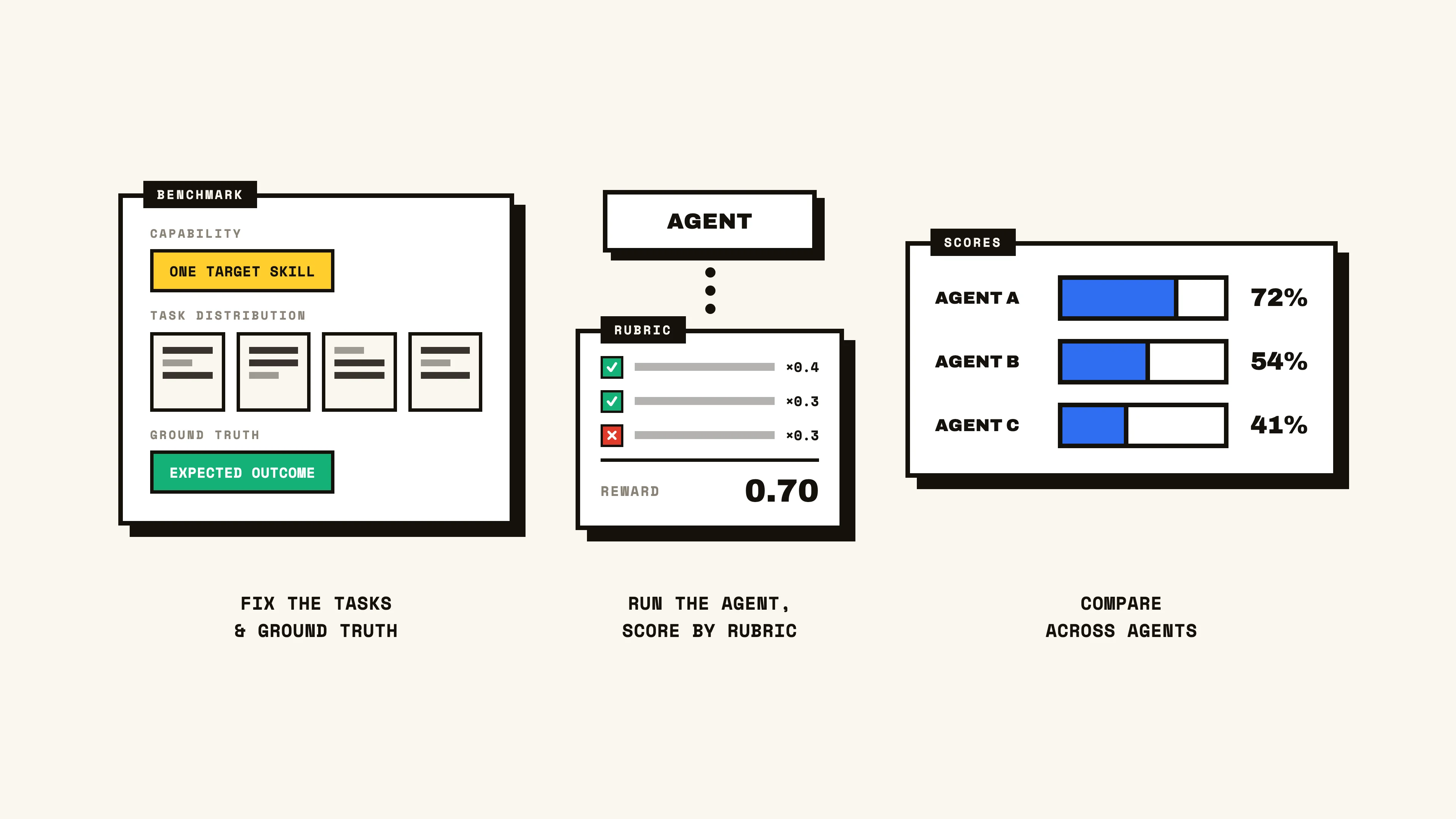
For each task, the starting environment is recreated by cloning the codebase’s pre-fix state and instructing the agent to fix the outlined issue. The agent then operates until it has implemented its fix, and the held-out test suite is run to verify if the fix is valid. Given an all green suite, the agent successfully completes the task and passes. If any test fails, the task is marked as a failure. While this description is specific to SWE-bench, we can extract some primitives that make up an agent benchmark:
- Capability — the specific skill or behavior being measured
- Task distribution — a representative set of inputs that test that capability
- Ground truth — the expected outcome each task is measured against
- Scoring method — how pass/fail (or a score) is determined
Building a benchmark then comes down to how well each of these primitives reflects the real-world capability you care about. For example, consider you’re building a financial audit agent. The benchmark would then be built around evaluating the core capability of an agent to identify violations in financial records. As such, tasks would be built where each consists of a set of financial documents containing known discrepancies that should be identified. These will vary in difficulty, topic, and density, representative of the range of conditions a real audit might present.
The agent is instructed, for each task, to inspect the documents and list the anomalies it finds. We can then evaluate its performance against the known ground truth using a measure like F1. Benchmarks provide two key advantages for agent engineering:
- A baseline and objective comparison across agents on a given capability
- A clear signal on improvement or regression on a given capability
On point two, performance on a benchmark gives us a concrete target to optimize against. In our prior example of the financial audit agent, we may hill climb its capability of identifying violations in financial records by running it on the tasks, observing where it fails, and making iterative improvements to increase score in subsequent runs. By improving performance on this benchmark, we close the gap between the agent’s current performance and the capability we’re after.
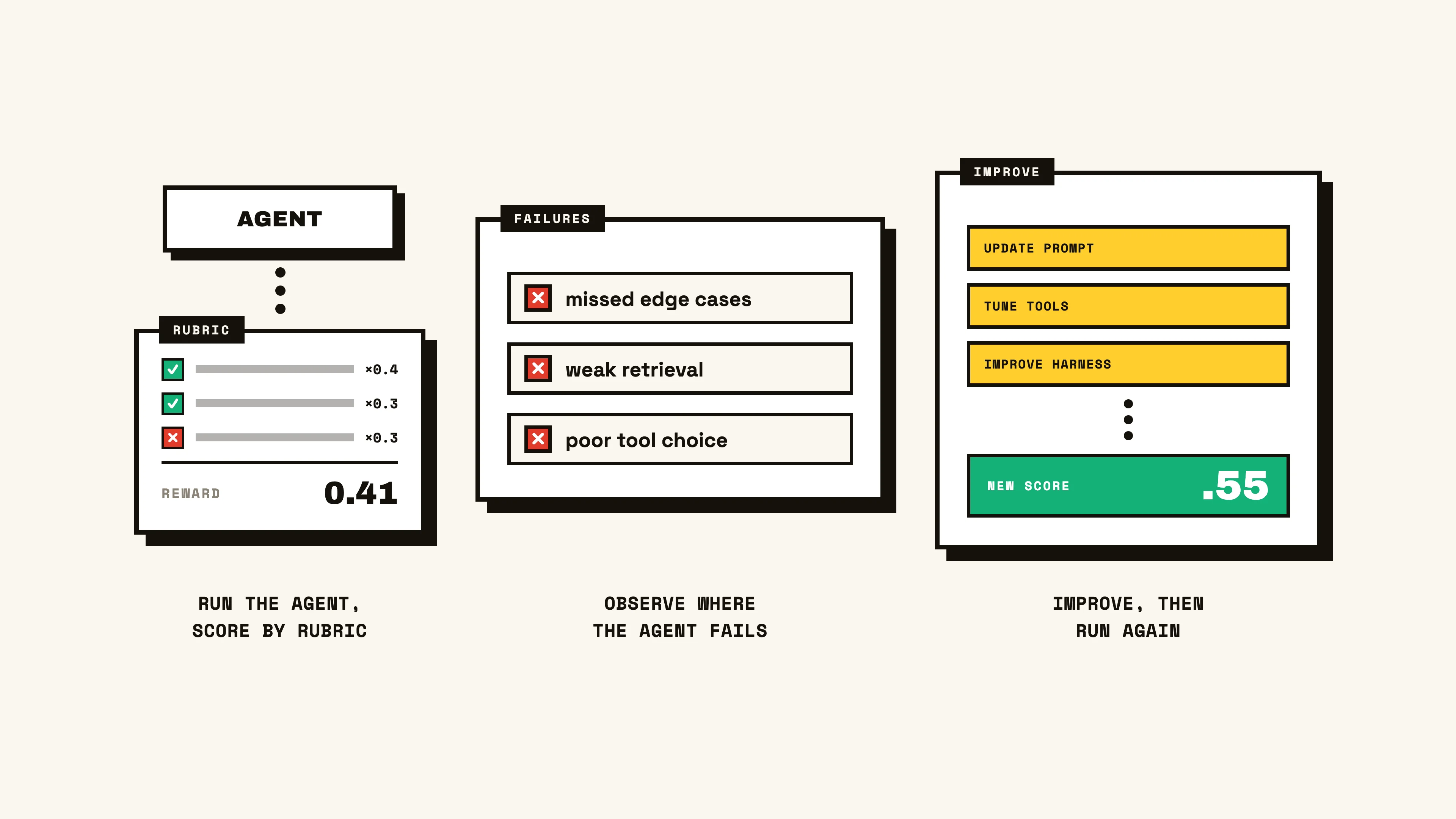
Due to the more nuanced nature of a benchmark, developing an effective and stable one can be the most difficult and involved effort across the eval types, but can unlock a true measurement and comparison of an agent’s capability against versions of itself and other architectures. Due to their specificity, the datasets, environments, and scoring methods are often bespoke to the capability. This is also where we see the largest adoption of a rubric, normalizing multiple scoring dimensions into a single weighted score commonly referred to as the reward.
Improving your Agent
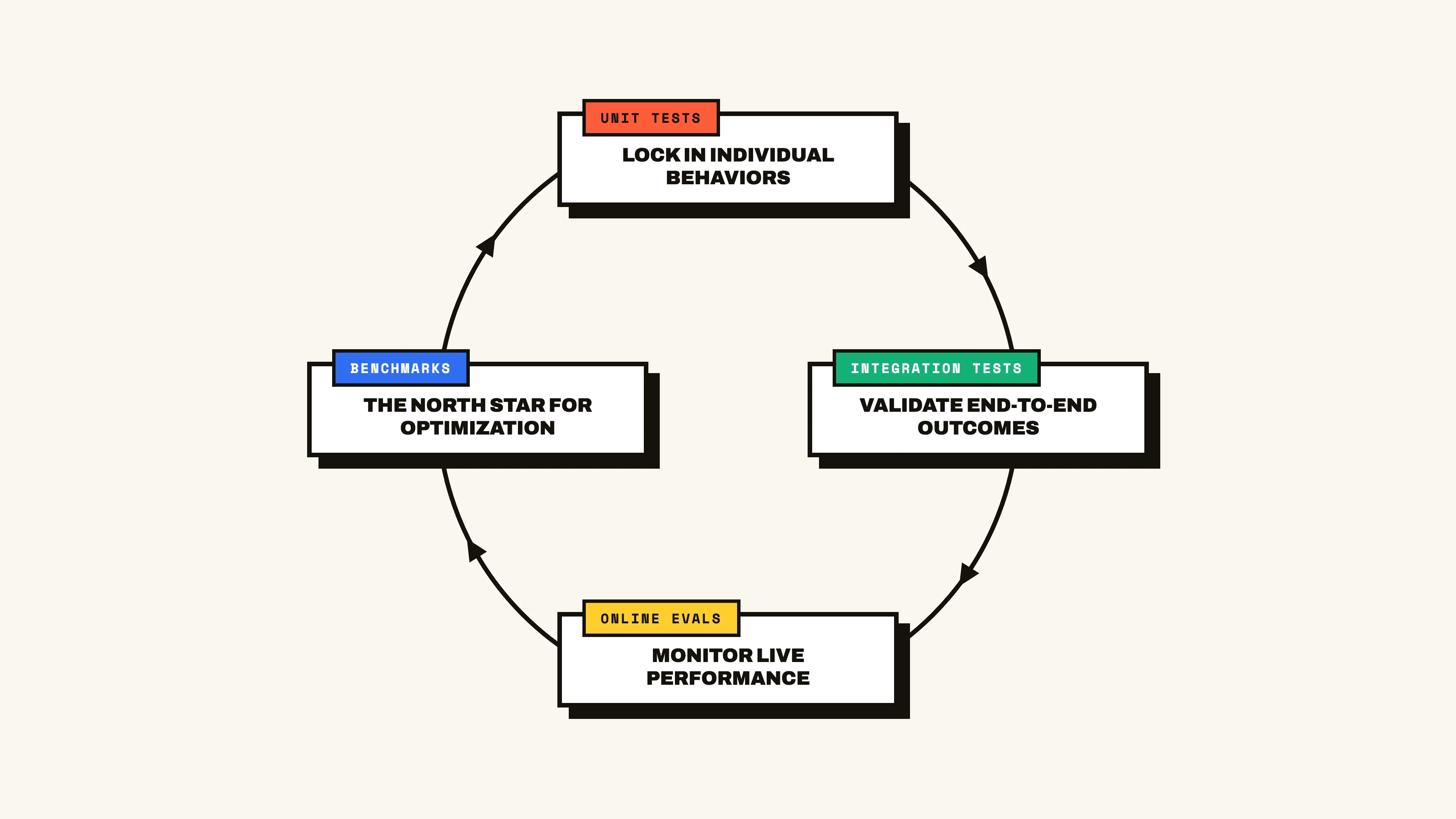
Together, these four eval types give the AI engineer a complete view into agent performance. Unit tests lock in individual behaviors, integration tests validate end-to-end outcomes, online evals monitor live performance, and benchmarks provide the north star for optimization. Each eval plays a distinct role in surfacing failure modes and ensuring that progress on one front doesn’t come at the cost of another. As always, the most powerful evals are those tailored specifically to your specific agent, so good luck building!