






Effective context engineering for AI agents
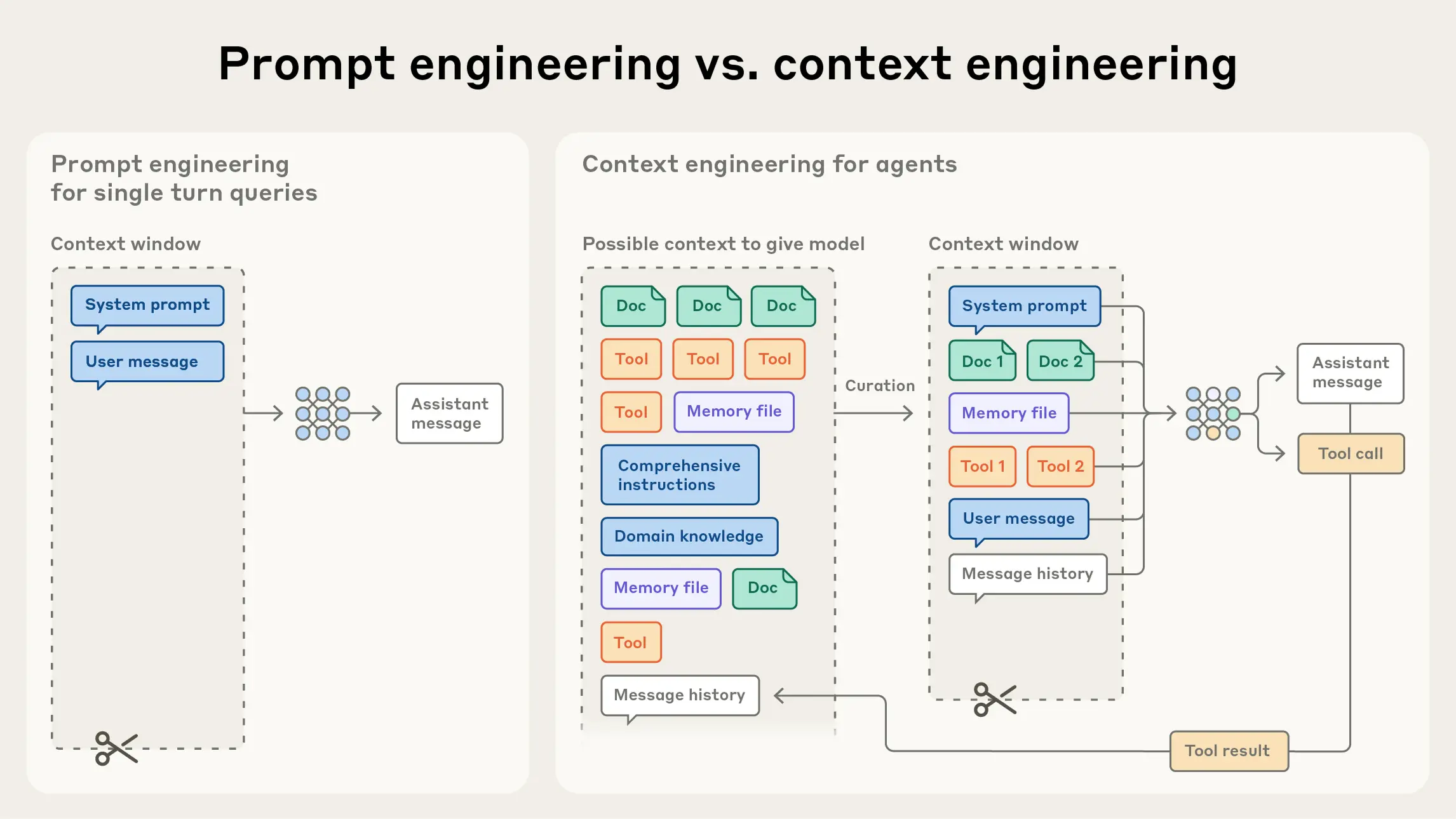
While the initial hype around language models coined the phrase "Prompt Engineering," prompting quickly evolved in mid to late 2025 with the more refined understanding of context engineering. This shift came about as a result of attempts to develop techniques that provide the most up to date and accurate data needed to condition the model's response generation, with the general assumption that the more relevant the context being provided is, the more accurate and helpful the generated response will be.
Context engineering, outside of just better prompting, has largely been developed alongside AI-specific retrieval systems that aim to search over massive amounts of domain knowledge, filter out irrelevant content, and capture the details necessary to answer related questions or inform intent to take actions within a limited context window. The two primary approaches to this are:
- Vector-based Similarity Search: Relying on embedding models to encode unstructured content into semantically-rich numerical values (vectors), that are then "placed" into a high dimensional vector space. Similarity retrieval happens by using the same embedding model to encode a target query and compare its placement in relation to other embedded documents, either literally via a distance calculation or through angle comparisons when standardized (e.g. cosine similarity).
- File System Search: Treating knowledge bases like a literal computer filesystem by storing both knowledge and generated artifacts in textual formats, often markdown. The LLM is then given relevant file navigation and modification tools to search through and interact with the data. This often operates as an LLM within a bash environment executing commands like
grep,ls,cat,cd,touch, etc., and cleverly relies on the LLMs' existing knowledge of programming.
Of course, relational databases are also still employed but find less use as they often rely on specific and accurate query language understanding, and are better at supporting tabular or numeric data. The above solutions fill the gap as the sources we require to inject domain knowledge are frequently less defined and structured.
Why is this needed? Anthropic puts it best in one of their tangential guides on Agent Skills:
The context window is a public good.
All operating context must fit within the confines and limitation of the provided context window, whose available resources grow more scarce as runs extend. With this, the engineering problem of context management becomes an optimization problem- minimizing the amount of tokens exhausted from the context window while maximizing the usefulness and relevance of what does get passed to the LLM. We broadly refer to this endeavor, then, as Context Engineering.
So how have we dealt with this limitation, and what's happening to improve the situation? Let's get into it.
Out of Context Window

Before we discuss further about context management, let's establish a baseline of what the context window even is. In use, this is the amount of tokens a language model can take as input, which guides its subsequent generation. With a chat based assistant, usage of the context window grows linearly as each input, action, and output is added to the sequence of messages and reingested turn after turn.
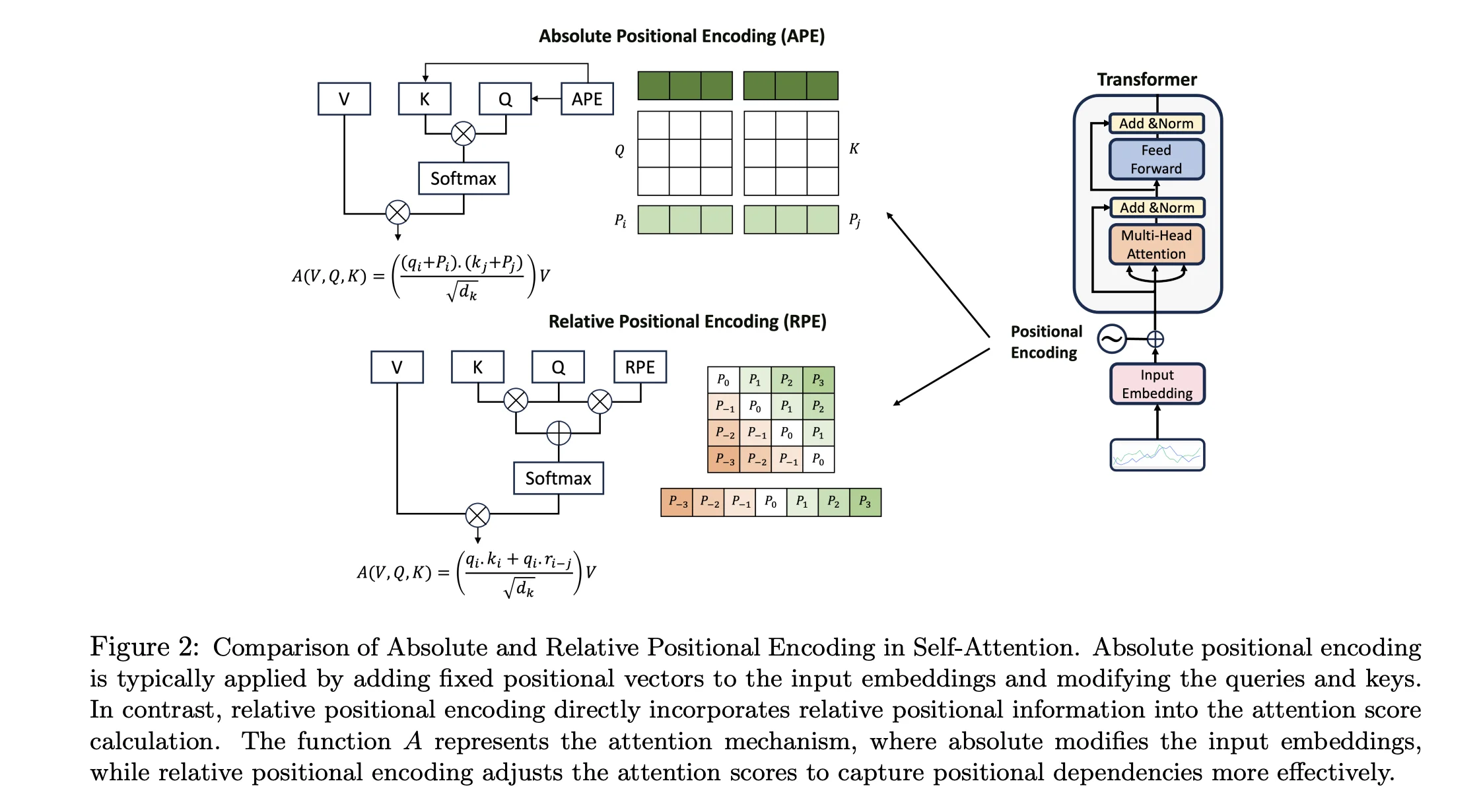
More technically, the context window is connected to the transformer and self-attention mechanism of current LLMs. Sequences are initially tokenized, and each token is input simultaneously into the model during a forward pass. Every token is then "understood" by the model through the self-attention mechanism, which allows the LLM's intrinsic interpretation of a token to be affected by the others around it. Self-attention is, by nature, order agnostic (more specifically permutation equivariant- the output changes correspondingly if you shuffle the input) so this must be assisted through positional encodings that are added to input sequences to inject relevant order information for the LLM. This helps the model understand the structure of language effectively, but introduces complexity and limitations when determining an LLM's maximum input sequence length (context window!). To understand this, we must consider the different techniques applied.
Historically, absolute positional embeddings were used that utilized a fixed-size table of vectors (one for each position 1, 2, 3, ..., N) that would get added to token embeddings. While initially effective, this imposed an architectural limit on context length, as the trained model would only be able to handle positions up to index N. Longer inputs would be out of bounds as a positional embedding for tokens that fall in N+1 would, very literally, not exist or be learned by the model. Modern models address this by encoding position not through addition, but through rotation.
You could have designed state of the art positional encoding
Rotary positional encoding, or RoPE, applies a position-dependent rotation to each token’s representation within attention (typically the query and key vectors), based on where it lands in the sequence. Intuitively, earlier positions have smaller rotations, later positions have larger rotations. Rotation, in this context, refers to a transformation of the embedding vectors which already have a direction and magnitude. RoPE affects the direction of the vector, but maintains the magnitude (i.e. how "strong" the embedding is). Going back to attention, when the model computes how two tokens relate via a dot product between the rotated query and key, the absolute rotations largely cancel out leaving a signal dominated by their relative offset. This results in the LLM learning relative positional patterns rather than absolutes, or in other words, the model would learn something like "tokens 10 positions apart behave like X," thus the interpretation of two tokens 10 positions apart would remain consistent, regardless of whether they're at position 1 and 10, or 1001 and 1010.
Positional Encoding in Transformer-Based Time Series Models: A Survey
Through removing the absolute position bottleneck and making positional encodings relative, we can generalize sequence length understanding without explicitly identifying every position, as the relational patterns between nearby tokens remain valid at extended lengths. That is not to say that RoPE solves all issues; both of these techniques still rely on effective training data that handles longer sequences. If all training data is 2048 tokens, LLMs will struggle to interpret, say, an input of 16,384 tokens unless explicitly taught how to.
In the end, balancing positional understanding, long sequence length model training, and (not expanded on here) additional hardware/memory constraints all play a part in crafting a model's context window. As advancements are discovered (YaRN: Efficient Context Window Extension of Large Language Models), training techniques improve, and additional compute is thrown at the problem, we've seen most modern LLMs' context windows increase over time, with some models like Google's Gemini series offering support for upwards of 1 million tokens in context.
Although these large context windows are now available for us to utilize, research and application have proven two points:
- We often have more context than can fit within a context window (our introductory argument)
- Not all context is treated equally by the model, despite being in the context window.
Moldy Context
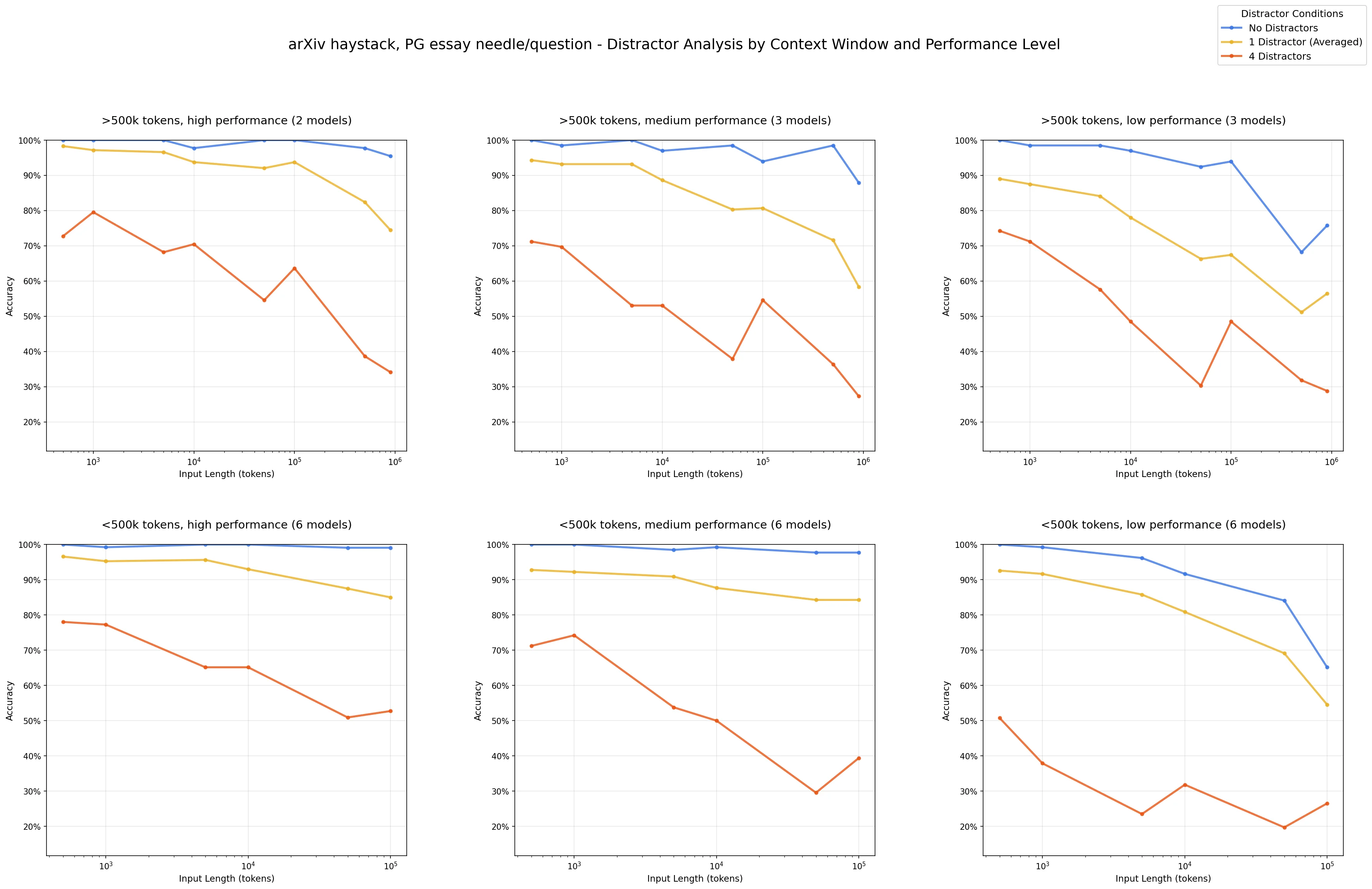
Context Rot: How Increasing Input Tokens Impacts LLM Performance
An unfortunate truth that's been discovered as context windows have been empirically tested is that models struggle to efficiently utilize all tokens equally under long input scenarios. This was discovered using multiple "needle-in-a-haystack" (NIAH) style tests, where a single gold answer is hidden among varying lengths of input sequences. Then, questions that could only be answered with the information contained in the gold context are queried. If a model can return an answer containing the context of the needle, then that is considered a success. All else a failure. Seen in the above graph from ChromaDB's research, there's a general decline in performance around 100,000 tokens, only exacerbated through the introduction of distractors. This observation led to the aptly named term: context rot.

Needle In A Haystack - Pressure Testing LLMs
An Aside About Distractors: While the main point of the NIAH overall was to demonstrate the decline in performance, the part on distractors is especially important to consider for applied AI. Real world unstructured datasets that contain thousands of related yet unorganized documents are common sets that exist and become candidates for RAG/other search & summary related LLM products. It is somewhat assumed that we can rely on the intelligence and processing of LLMs to make sense of the noise, but anyone who has built enterprise grade AI search and summary at this scale, myself included, will have anecdotal evidence about LLMs' lack of nuance when interpreting the data itself. I've found that much of this is a result of the distractor concept that Chroma suggests, where the interpretation of similar, yet different, data that's been retrieved or processed together is less robust than clearly delineated topics. Often, LLMs must have a broader understanding of the similar context around a topic to do more minute analysis, which requires more advanced management, navigation, and delivery of context as a complete system.
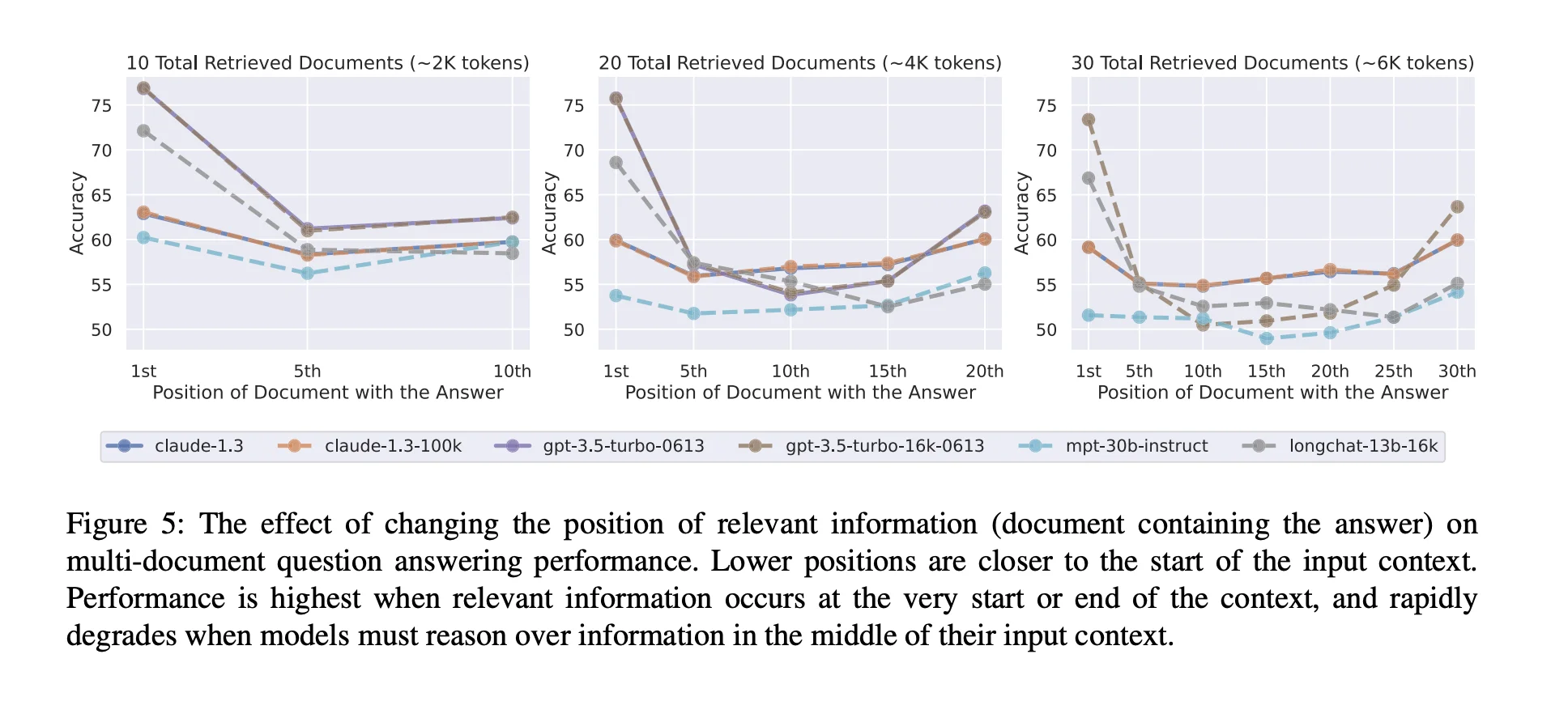
Lost in the Middle: How Language Models Use Long Contexts
This phenomenon has been around since models like GPT-3.5 became more applicable, and documentation of recency and positional bias remain relevant as ever, however, the core reason as to why this happens is still an ongoing topic of discussion. It's unclear exactly what causes this, but some hypothesize it may be:
- Training Data Distribution - It is difficult to provide many concrete examples of how to actually use and manage extremely long context (e.g. multiple books worth of information) and training example sequences are often shorter; the model therefore learns priors that often work in typical length data but don’t reliably generalize to long-context evidence scattered throughout.
- Architectural Limitations - RoPE techniques can exhibit a long-range decay that biases attention toward nearer tokens as context grows, and softmax attention can disproportionately allocate to early tokens, which together reduce effective mid-context retrieval.
But further mechanistic interpretability research is needed to say conclusively the root cause of context rot.
The 5th Stage of Grief
Unless you are part of the few actively furthering the field of computer science and solving these issues at a foundation model training level (hit me up if you are, that sounds cool!), we must accept these limitations and work to define elegant solutions within these constraints. Up until recently (February 2026 at the time of writing), solutions to this problem centered around the technique of Retrieval Augmented Generation, in which documents were (sometimes) chunked and embedded into vector databases. Relevant documents were then retrieved and delivered into the context window via a semantic-similarity calculation, in which the query was compared relative to all other documents and those up to a certain similarity threshold were returned. This technique has been widely accepted, and, given a limited document set, tends to work fine for more defined use cases. I myself have explored this extensively, you can see a further collection of my resources, experiments and tools here:
Retrieval Augmented Generation (RAG) Playlist
RAG, in this sense, frames context management as a search and retrieval problem, positing the question:
How do we get the right context INTO the window?
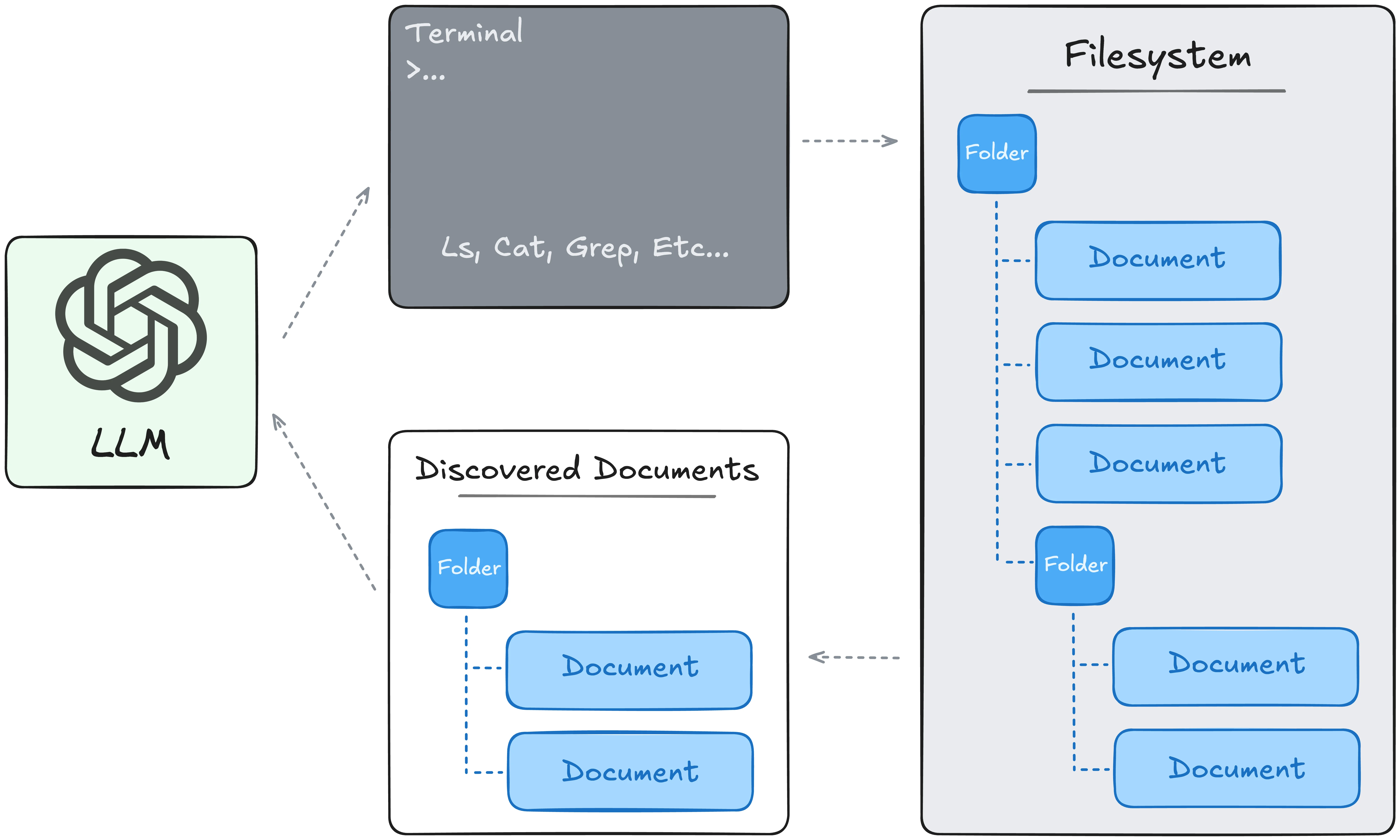
While effective, scaling RAG systems becomes complicated as optimization becomes more an issue of improving a search engine than an AI system. Which brings us to the second technique hinted at in the introduction, filesystems. This approach, discovered and popularized by coding agents like Claude Code, Cursor, and Codex, reframes context delivery as a navigation problem in which the LLM directly explores the context. This changes the question being asked to:
How do we let the model NAVIGATE context itself?
Filesystem-based agent harnesses enable LLMs to find the right context by providing an environment and toolset to the LLM in the form of a literal computer terminal. LLMs then write valid commands which are executed, and the results returned back in context. Immediately, this allows a much more flexible system of context delivery than available with database-related retrieval, as LLMs have an intrinsic understanding of the environment due to a massive amount of learned programming knowledge. We bypass the technical baggage of search systems, and enable an LLM to progressively discover information- searching (can be semantic, pattern or keyword here too!), previewing, and opening content that's only deemed relevant through the intelligence of the model.
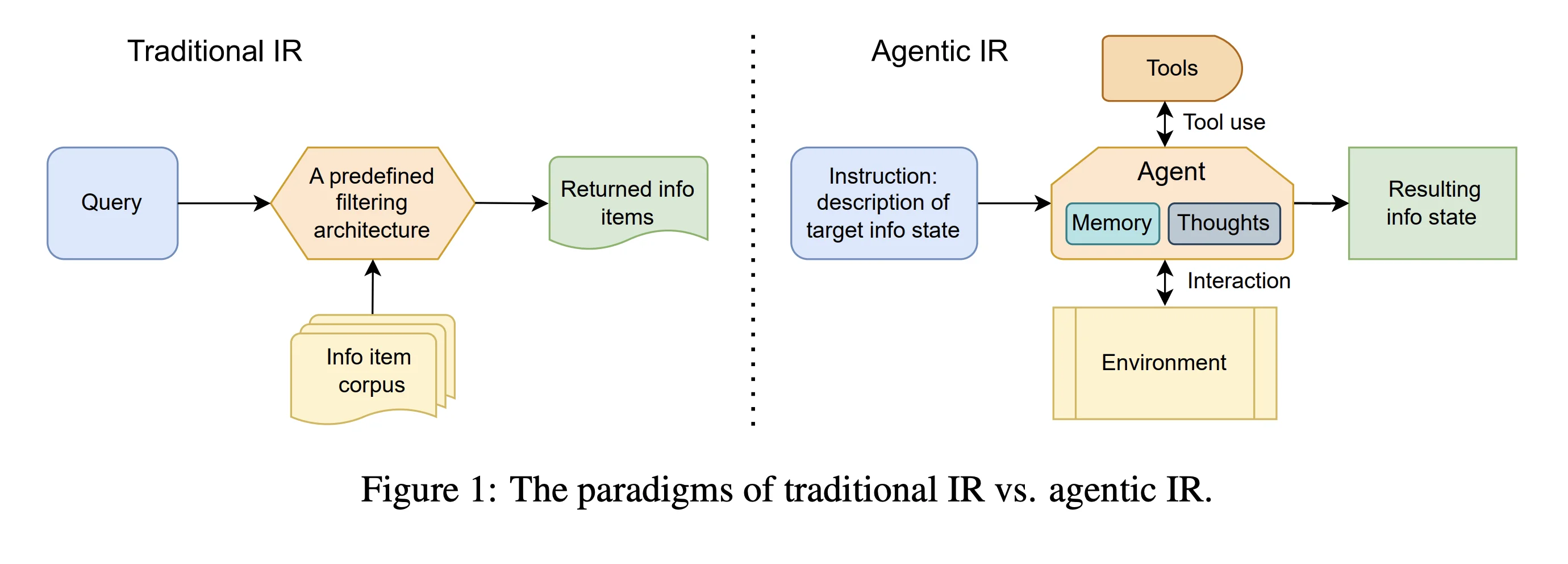
These findings from popularized coding model frameworks (see deepagents) bring us back to the scenario of effective context management. The same ideas posited here are applied in a more scientific manner through Recursive Language Models, or RLMs.
Recursive Language Models
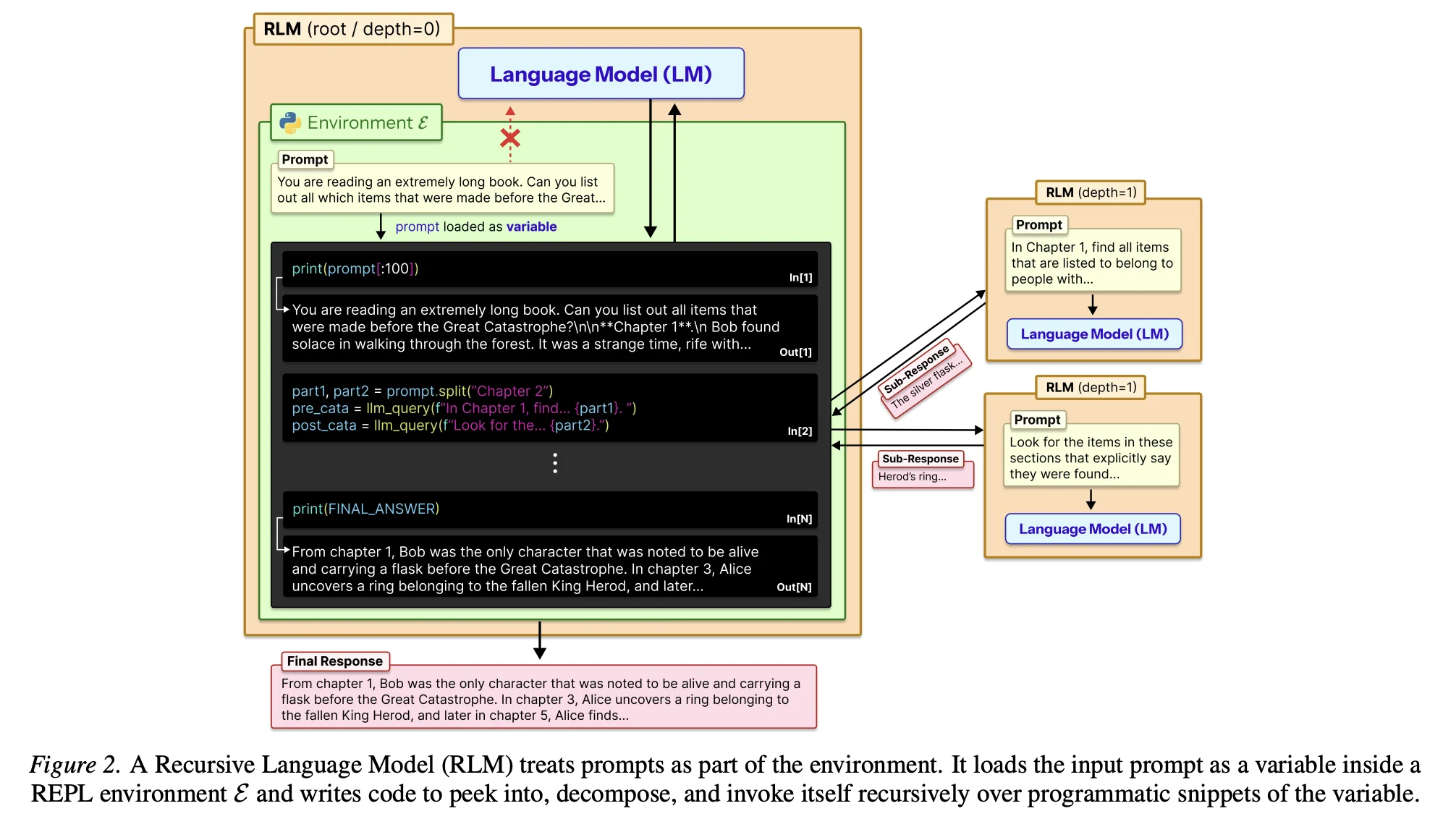
The RLM framework "treats long prompts as part of an external environment and allows the LLM to programmatically examine, decompose, and recursively call itself over snippets of the prompt." In practice, this means that a prompt is passed as a variable in a Python REPL environment to the model. The LLM can then perform operations on the prompt as if it were any variable in Python through writing and executing code. Along with metadata about the prompt, instructions, and examples, the LLM is encouraged to use the REPL environment liberally to explore and navigate the prompt in an iterative manner. Importantly, the "recursive" nature of RLMs comes from the ability for the operating LLM to call additional LLMs through an llm_query() function. These function-called LLMs are not able to call additional LLMs themselves (i.e. depth of 1), but are useful for delegating atomic tasks into a fresh context window. This leads to unique scenarios where you can orchestrate and parallelize LLM calls via code execution:

Note: Using this sub-agent technique is also referred to sometimes as context folding.
The LLM then loops in this environment until it submits a final answer through an executed FINAL_VAR(). The RLM technique proves that LLMs can scale their understanding of content far exceeding the context window (10M tokens+) when given the correct environment and tools for discovery and navigation of information.
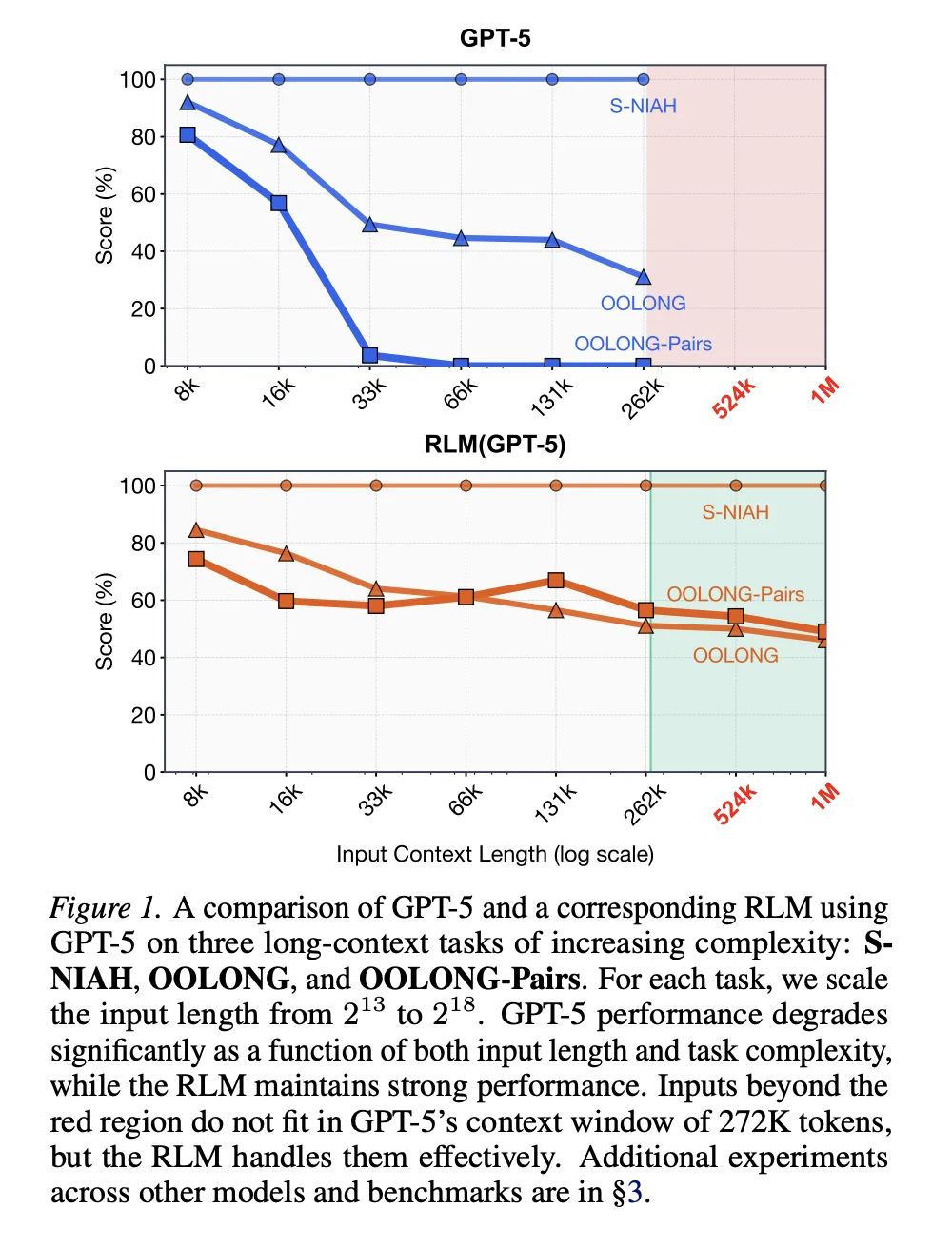
An interesting side effect of creating an environment with a verifiable task of long context question and answering is that this can be used both as a reinforcement learning environment or as a generator to create supervised fine-tuning compatible examples. The authors of the RLM paper proved that using SFT on these examples boosted performance and instruction following, while the Prime Intellect team found the same with RL techniques. Along the way, the model learns and evolves to understand how to manage its own context most effectively.
Note: Curious about reinforcement learning for LLMs? Check out my Reinforcement Learning with Verifiable Rewards blog here!
RLMs offer a compelling solution for context handling, combining pre-established techniques of summarization with the context folding of sub agents all while capitalizing on already trained code understanding and generation capabilities. We've already seen this ability emerge as a result of coding agents' behavior, so Zhang et al.'s formalization of this into concrete research presents a worthwhile argument.
Practice Makes Perfect
The field of context management is evolving fast, now we're on the latest trend of filesystem-based agent harnesses giving LLMs the tools to navigate, delegate, and better handle long-context and long-horizon scenarios. In practice, I've found this offers a tradeoff between latency and accuracy- traditional RAG systems offer simplified and quick context search and delivery while RLMs and related deep agent frameworks trade speed for increased inference time compute, widening search and exploration to better understand and process context. In situations where analysis can be asynchronous and requires broad contextual understanding, an RLM-style framework is the way to go. For scenarios like chatbots where latency plays a big factor in user experience, faster and narrower retrieval may be better suited. As always, test each and determine what works best for your use case empirically!