

After a base large language model is pretrained, it goes through multiple rounds of post-training to shape and align how it responds. This post-training tends to focus on refining traits such as what it knows, how it reasons, and the style it uses. To do this, most modern systems rely on three main levers:
- Supervised Fine-Tuning (SFT) to teach formats and tasks by imitation,
- Preference Training to prefer better answers over worse ones, and
- Reinforcement Learning (RL) to optimize for sequence-level goals and generalize procedures.
These techniques are used in different ways at different times in the model’s training lifecycle depending on the alignment goal, often in an order that follows:

- Pre-Training a language model using next-token prediction at scale.
- SFT for base instruction-following + tools + formatting.
- Preference Training to push general answer quality and safety (RLHF, DPO/KTO or reward-model + small PPO).
- Targeted RL where you have strong rewards (coding, math, tool-using agents, browsing).
- Continual Refresh with new data, procedures, and preferences as they become available.
Training language models to follow instructions with human feedback
Beyond pretraining and SFT, reinforcement learning is central to both preference training and (obviously) targeted RL above. For more on how RL drives alignment and preference optimization, check out my other resource on LLM alignment in post-training here!
A Survey of Reinforcement Learning for Large Reasoning Models
However, with a general saturation of quality pre-training data and diminishing returns for scaling supervised fine-tuning techniques, we’ve seen many labs innovate more heavily with reinforcement learning techniques.
In this blog we’ll cover:
- A light refresher of reinforcement learning in the context of large language models
- When and why RL is used with LLMs
- The adoption of reinforcement learning with verifiable rewards
- How to create your own RL environment and train an LLM within it!
Refresher of LLMs & Reinforcement Learning
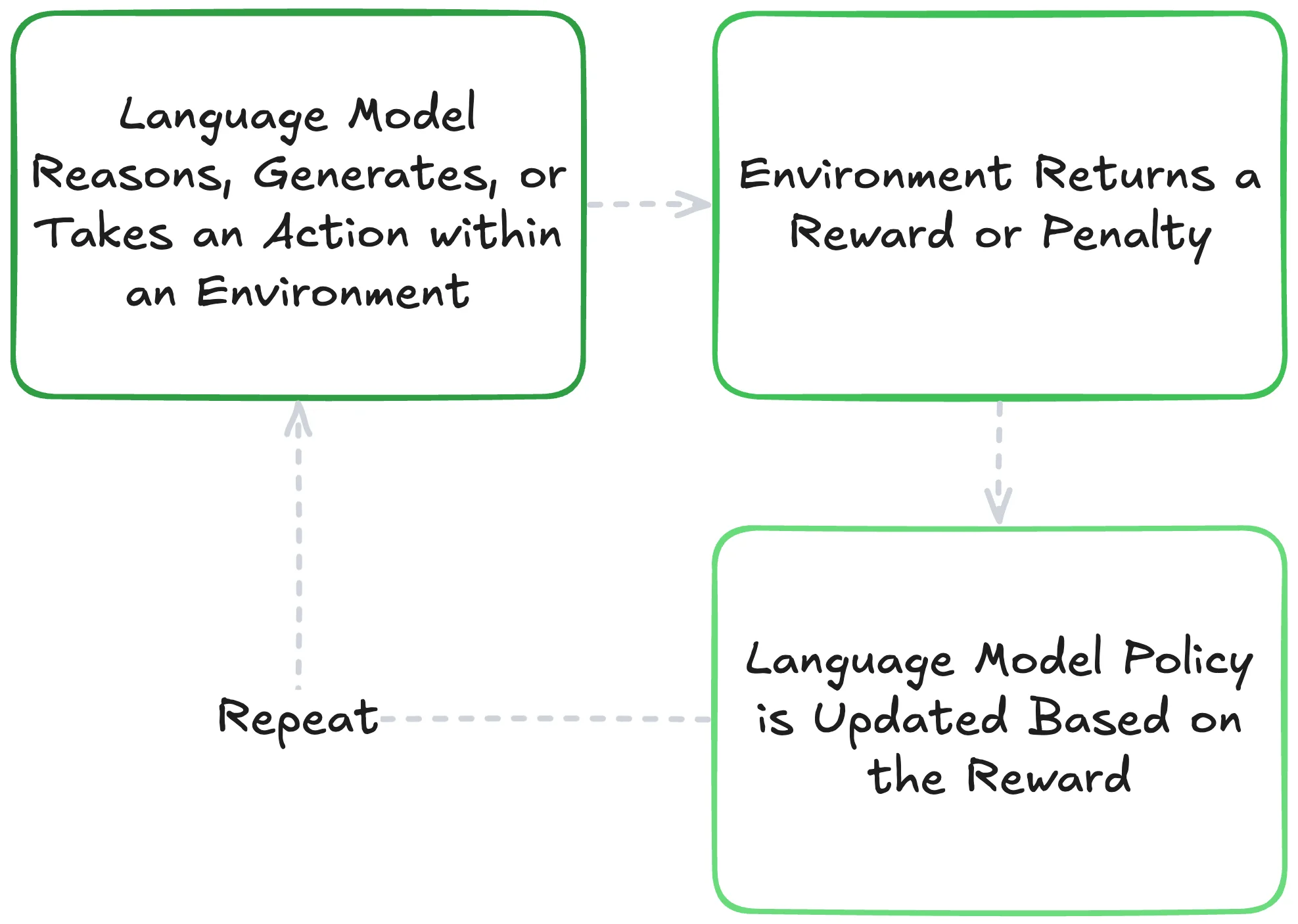
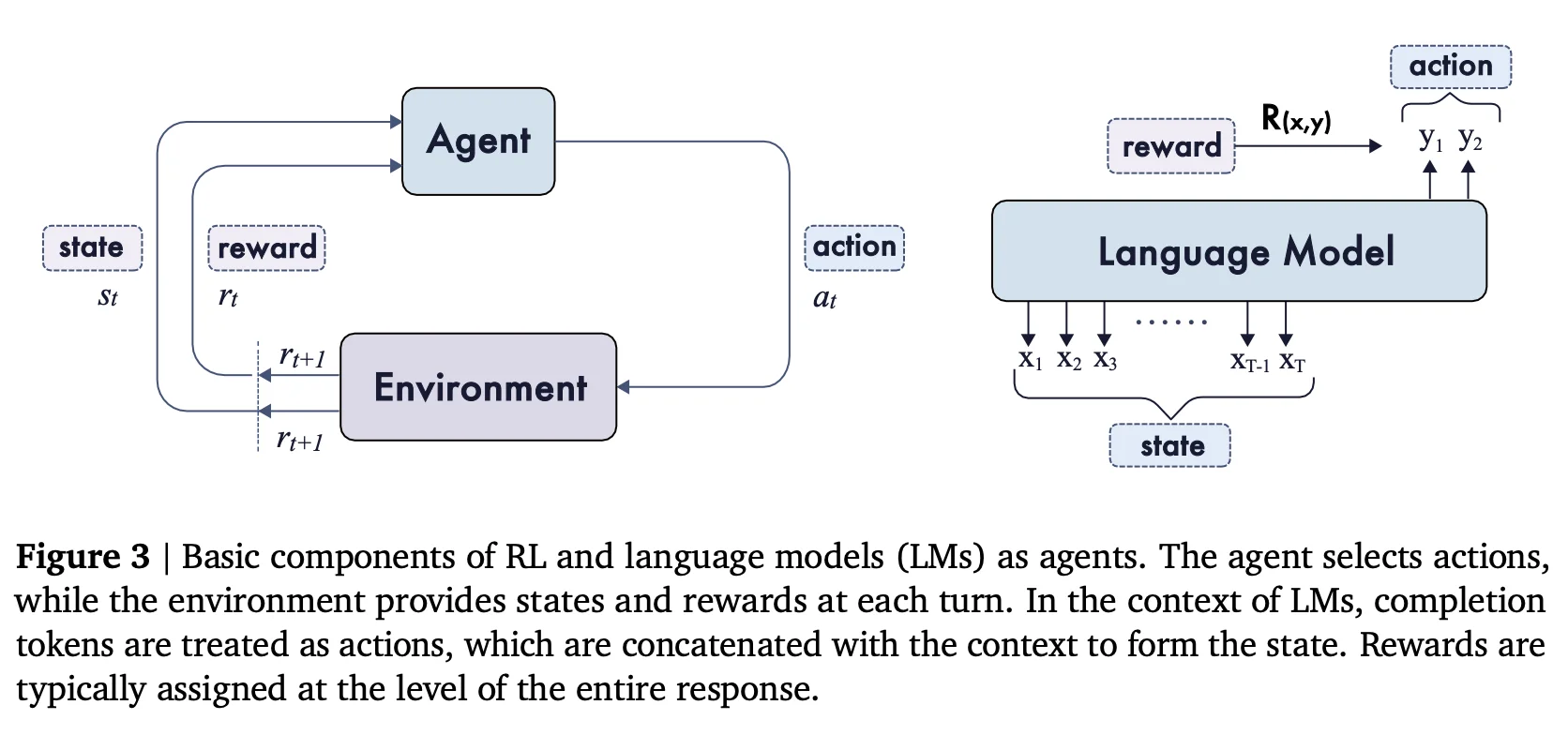
Reinforcement learning trains an agent (in this case, the LLM) to interact with an environment (the task context) by taking actions that maximize cumulative reward over time. The general objective is to learn a policy that achieves the highest expected total reward.
A Survey of Reinforcement Learning for Large Reasoning Models
The policy is the language model itself, which generates a sequence of tokens in response to a prompt. These tokens either constitute the generated text or can represent complex behaviors such as further actions via tool or function calls, especially in “Agentic” scenarios. Depending on the granularity, the action may be an entire sequence, a token, or a segment. This happens within a defined environment that provides the context within which the model generates. After generating, the environment provides some form of feedback based on the actions incurred by the policy, commonly referred to as a reward. Rewards are the positive or negative scalar values defined by whoever created the environment that signal positive or negative behavior. These signals are then processed via RL algorithms, like proximal policy optimization, to adjust (i.e. affect the underlying weights of) the policy to maximize the cumulative reward over time.

A high-level visualization of RL
When RL is Used
Before any RL is applied, a base LLM typically undergoes supervised fine-tuning (SFT) on curated input & output pairs to establish a reliable reference policy. SFT helps:
- Make the model consistently follow instructions and formatting contracts,
- Set tone/safety/refusal patterns,
- Teach basic tool use, and multi-turn etiquette,
When to use supervised fine-tuning for Gemini
SFT is highly effective for teaching behaviors and injecting domain knowledge, but it doesn’t directly optimize for global outcomes, which is where reinforcement learning was introduced.
RL’s initial rise was tied to post-training strategies for ‘alignment’ through techniques like Reinforcement Learning from Human Feedback (RLHF). RLHF was one of the initial RL methodologies for human alignment in recent years and involves training an explicit reward model, which is typically a secondary model trained on human preference rankings (e.g., which model response is preferred over another). This reward model then provides the agent (the LLM) with a reward signal during policy optimization. This was used to train LLMs to generate more useful, desired, safe, and reliable outputs in common open-ended environments like ChatGPT. Advancements were made with techniques like process reward models that provide evaluations of intermediate steps for fine-grained credit assignment earlier in the decision sequence, or direct policy optimization that forgoes RL by training on pairwise examples.
More recently, reinforcement learning has proven additionally useful when applied to more verifiable tasks- mostly spurred by the release of DeepSeek-R1 that showed emergent reasoning capabilities learned in language models as a byproduct of RL.
Reinforcement Learning with Verifiable Rewards

DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
While methods like RLHF, DPO, etc. are fundamentally oriented toward alignment and refining the model’s behavior based on subjective human/AI preferences, reinforcement learning with verifiable rewards (RLVR) focuses on automatic and objective feedback (like answer correctness) to help models develop procedural capabilities through objective, verifiable feedback signals.

A Survey of Reinforcement Learning for Large Reasoning Models
Unlike RLHF’s reliance on subjective human preferences, rule-based rewards provide scalable and reliable training signals for RL and are low hanging fruit for optimizing LLM performance on tasks with clear objective ground truth and deterministic outcomes, such as mathematics, code generation, logical proofs and more. Models like OpenAI’s o series and DeepSeek-R1 were the first to demonstrate that training LLMs with verifiable rewards enables models to learn and generate procedures. What appears as “reasoning” is the emergent byproduct of these models learning to construct, execute, and adapt procedural sequences that reliably achieve verifiable outcomes.
RLVR has gained popularity for its ability to teach LLMs procedural generalization through reinforcement learning’s natural exploration mechanisms. By optimizing against objective, verifiable outcomes, models learn to navigate complex problem spaces, develop specialized capabilities, and improve at long-horizon, multi-step tasks. This approach offers practical benefits by eliminating the need for separate critic or reward models, and can achieve strong results with limited training data.
Composer: Building a fast frontier model with RL
Some examples of where RLVR has excelled include:
- Autonomous coding agents (Cursor Agent, Claude Code, Codex): These systems handle entire development workflows by creating multiple files, running tests, debugging failures, and iterating until specifications are met. The RL signal comes from end-to-end task success, test coverage, and successful deployment metrics.
- Production assistants like ChatGPT and Claude: While these appear conversational, they increasingly incorporate RL for capabilities like following complex multi-step instructions, maintaining consistency across long contexts, and successfully using tools.
- Browser and GUI automation: Agents learn to navigate interfaces, fill forms, and complete multi-step workflows where success is clearly defined (e.g., successfully booking a flight, extracting specific data, or completing a purchase).
RLVR produces important emergent capabilities, including reasoning behaviors, sophisticated tool use, and complex procedural learning. While the aforementioned DeepSeek and OpenAI o model examples show this emergent reasoning, recent research from Apple, Reinforcement Learning for Long-Horizon Interactive LLM Agents, documents clearly how procedures can improve.

Given the environment AppWorld, which simulates and tests an agent’s ability to interact “with simulated consumer apps (including email, payments, music, shopping, phone, and file system),” the researchers found that through RL training the LLM learned to:
- Avoid open-loop control when calling tools (checking results rather than assuming success)
- Consistently read API documentation before attempting calls
- Make fewer assumptions about system states
- Use fewer placeholder values in API calls
- Persist through API errors rather than giving up
Despite only using a simple task completion reward! These findings have brought a renewed interest in applying and researching RL techniques across the ML community, with researchers and practitioners eager to discover these emergent capabilities for their own domains.
To sum up everything we’ve discussed so far: SFT is the foundation that teaches an LLM what to do and how to sound by maximizing imitation of curated behavior. Preference-based RL then reshapes that behavior toward subjective desirability, while RL with verifiable rewards pushes toward objective task success and procedure generalization.
With that in mind, let’s cover how to create your own RL environment, define verifiable rewards and train a LLM using RLVR approaches.
Creating an Environment
As emphasized before, the environment is the most important part of the RLVR loop and encompasses the world in which the LLM learns and operates, its action space, and the reward signals it will receive that should encourage desired behavior.
When developing this kind of environment the fundamental consideration is, of course, verifiability. The strongest environments have clear binary signals (e.g. Correct or Incorrect, Pass or Fail, Working or Not) that can be determined automatically and objectively from the environment. While fuzzy or continuous rewards are possible, binary pass/fail signals offer superior learning efficiency, eliminate ambiguity, provide consistent training signals, and scale without human intervention.
Jason Wei, AI Researcher and contributor to OpenAI’s o1 and Deep Research models, captures this sentiment in the ‘Verifier’s Rule’:

The ease of training AI to solve a task is proportional to how verifiable the task is. All tasks that are possible to solve and easy to verify will be solved by AI.
Asymmetry of verification and verifier’s rule
In other words, we can train models to tackle complex problems as long as we can easily check their solutions!
Defining our Environment - PII Masking
For our example environment, the procedure I wish to teach an LLM is redacting personally identifiable information (PII) identification from text. This is inspired by the dataset open-pii-masking-500k-ai4privacy created by ai4privacy which provides half a million examples of this task being done.

This is a perfect scenario as we have both a clear input prompt (the original text) as well as an expected outcome (redacted transformation) that can be directly verified. However, identification and masking is still complex enough to not be trivial given the occasional subjectivity of the data and large number of kinds of PII.
With this in mind, I created a subset of the original dataset that kept just the US english examples, and removed the various PII labels in favor of a generic [PII] mask in place. Additionally, I include metadata about the count of PII labels expected from the given examples. A single example looks like:
{
"question": "06382.21617 contacts Orianne regarding their ride on South Western Avenue, near 8502 in Hubbardston.",
"answer": "[PII] contacts [PII] regarding their ride on [PII], near [PII] in [PII].",
"info": {"pii_count": 5},
"task": "privacy_masking"
}
This dataset can be found at: AdamLucek/open-pii-masking-en-us-30k
Creating Reward Functions
With our scenario and dataset figured out, the important next step is defining the task specific rewards. With RLVR the two primary types of rewards tend to fall into:
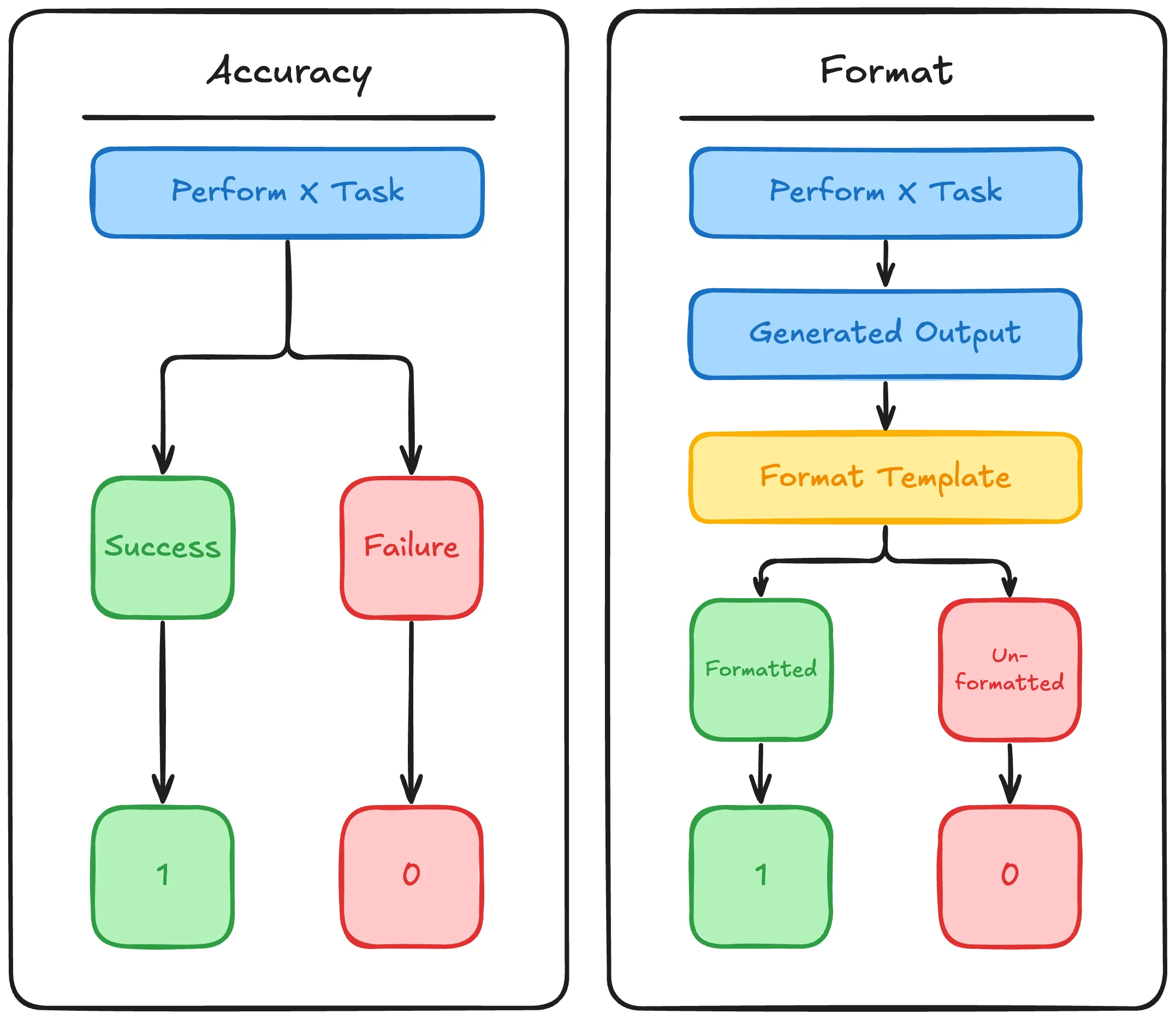
Accuracy Rewards (Binary Verification) Provide clear pass/fail signals based on objective correctness, for example:
- Task completion: Binary success in achieving specified end states (e.g., successfully booking a flight, extracting the right data)
- Mathematical solutions: The policy produces answers within prescribed delimiters (e.g.,
\boxed{...}), which automatic checkers compare against ground truth - Code execution: Unit tests, compilation success, and runtime behavior provide unambiguous feedback
Format and Structural Rewards These impose constraints on how models organize their outputs, for example:
- Delimited reasoning: Requiring chain-of-thought between markers (e.g.,
<think>and</think>) - Output structure: Enforcing JSON schemas, function call formats, or specific response patterns
- Length constraints: Penalizing overly verbose or too-brief responses
For scenarios where full verification isn’t possible, we turn to heuristic proxies, or lightweight signals that correlate with quality without having direct ground truth.
- Tool usage efficiency: Rewarding minimal API calls or optimal tool selection sequences
- Response coherence: Character/token length ratios, presence of required sections
- Partial matching: Giving credit for solutions that are partially correct or contain key components
- Performance metrics: Speed of solution, computational efficiency, memory usage
More complex or nuanced evaluations may still rely on fuzzy signals provided by generative models. This is where a form of llm-as-a-judge for tasks where human-like judgment is needed but human feedback isn’t scalable:
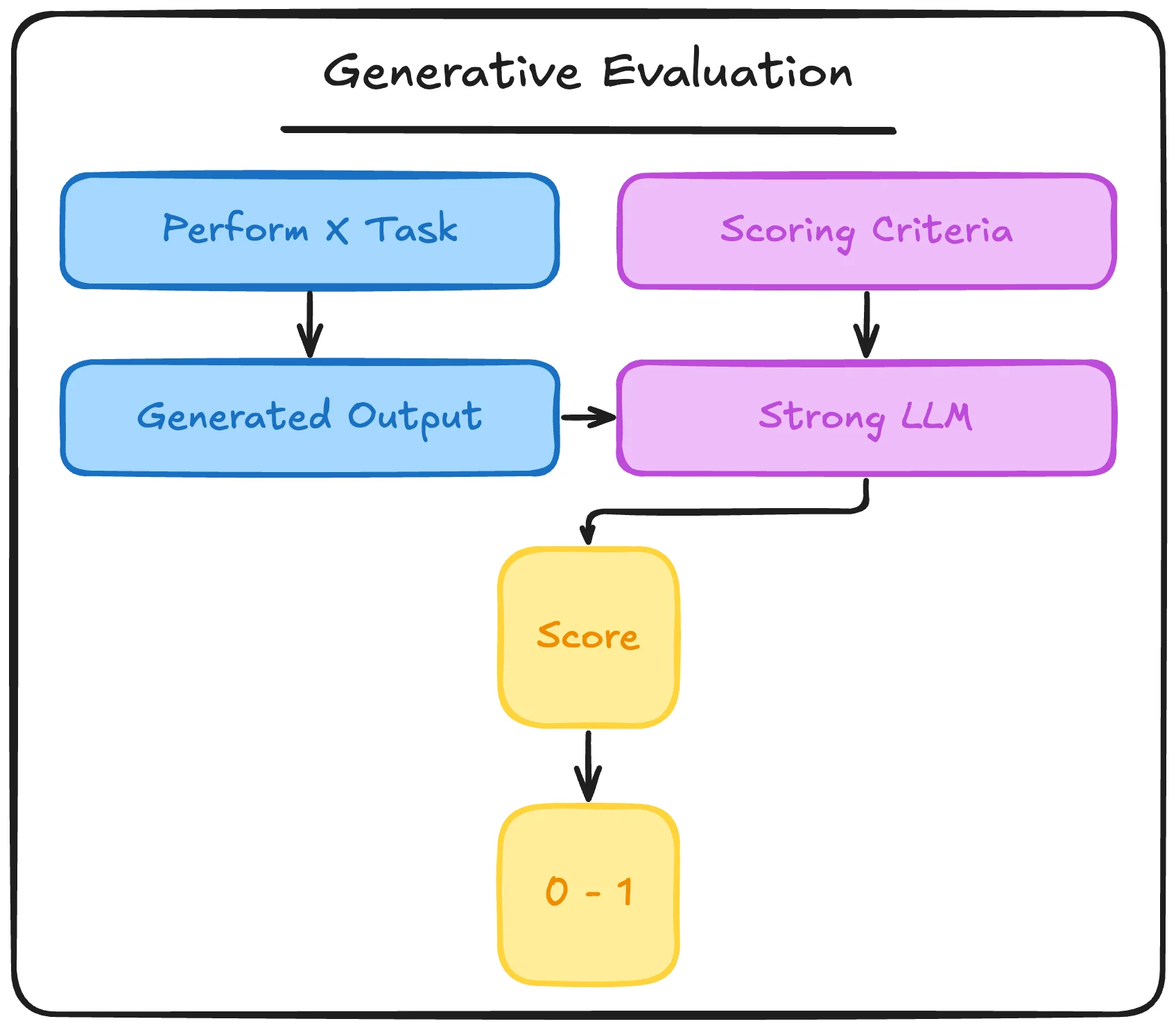
- Generative evaluation: Using a strong LLM to assess response quality, producing nuanced text feedback that’s commonly mapped to scalar rewards
- Self-play: The model improves by playing against itself or its past versions, generating data to refine its policy.
- Model debate: Multiple models argue contrasting answers and a judge selects the winner to steer optimization.
It is best to start with straightforward Accuracy and Format rewards before turning to more complicated reward setups, as heuristic or LLM based rewards can introduce unintended bias and instability, undermining the proposed benefits of RLVR.
Figuring out the best combination of these reward signals is a creative process, where the environment developer defines and combines rewards to best represent the success or failure of the task and procedure being learned. The best reward functions are those that closely align with real-world success metrics while remaining automatically verifiable.
Defining our Rewards - PII Masking
For our PII masking environment, I am going to define three rewards:
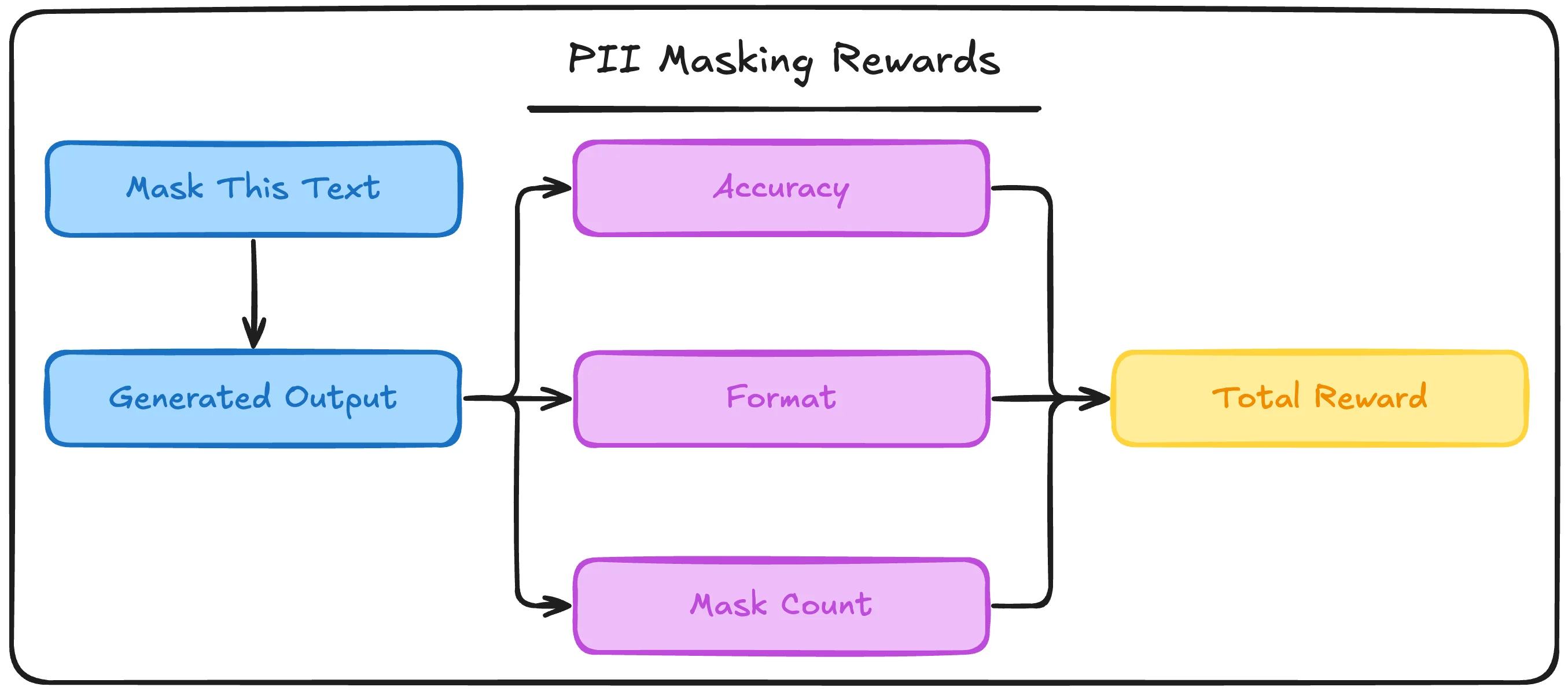
Accuracy Reward: Binary check if the model generated text is exactly equal to the expected masked output
Format Reward: Binary check if the model generates its response within expected XML tags <masked_output></masked_output>
Partial/Heuristic Signal: Binary check if the count of PII masks equals the expected count
The accuracy reward is, of course, the most important reward here followed by a lightweight format reward to ensure parsing the output is reliable and easy. The final mask count reward is intended to signal that the amount of masks included is correct, even when the final accuracy isn’t.
With our dataset created and the theory behind our environment and reward functions down, we can turn towards implementation!
Programming the Environment with Verifiers
To combine all of our theory into implementation, we’ll be using the Verifiers library. Verifiers provides a robust toolset to create, use, and share RL environments for LLM training and evaluation, popularized and created by Will Brown, further commercialized via Prime Intellect.
Our fully constructed environment looks like:
import verifiers as vf
from datasets import load_dataset
def load_environment(
num_train_examples: int = -1,
num_eval_examples: int = -1,
random_seed: int = 42,
) -> vf.Environment:
"""
Defines and returns the PII Masking Environment.
"""
# ===== System Prompt =====
system_prompt = """Replace all personally identifiable information (PII) in the text with [PII] tags.
PII includes: names, dates, phone numbers, SSNs, account numbers, addresses, email addresses, and any other identifying information.
Examples:
Input: Ticket Reservation for Florije: 'one ticket for Madame on October 8th, 1990'
Output: Ticket Reservation for [PII]: 'one ticket for [PII] on [PII]'
Input: User account recovery: "Hi Arljind Komla, your account recovery key is 426220045."
Output: User account recovery: "Hi [PII], your account recovery key is [PII]."
Return ONLY the masked text wrapped in masked_output XML tags:
<masked_output>
[Your masked text here]
</masked_output>"""
# ===== Dataset =====
# Load Dataset
ds_all = load_dataset("AdamLucek/open-pii-masking-en-us-30k")
dataset = ds_all["train"]
# Limit Training Examples if Specified
if num_train_examples != -1:
dataset = dataset.select(range(min(num_train_examples, len(dataset))))
# Calculate eval size
# Default to 20% of train dataset
if num_eval_examples != -1:
test_size = min(num_eval_examples, max(1, len(dataset) - 1))
else:
test_size = 0.2
# Split Dataset
split = dataset.train_test_split(test_size=test_size, seed=random_seed, shuffle=True)
# Select Training and Evaluation Datasets from Split
dataset = split["train"]
eval_dataset = split["test"]
# ===== Parser =====
# Define Parser
parser = vf.XMLParser(fields = ["masked_output"], answer_field = "masked_output")
# ===== Reward Functions =====
# Format Reward Function
format_reward = parser.get_format_reward_func()
# Exact Match Reward Function
def exact_match_reward(parser, completion, answer) -> float:
parsed_answer = parser.parse_answer(completion) or ""
return 1.0 if parsed_answer.strip() == answer.strip() else 0.0
# PII Count Reward Function
def pii_count_reward(parser, completion, info) -> float:
parsed_answer = parser.parse_answer(completion) or ""
expected_count = info.get("pii_count")
actual_count = parsed_answer.count("[PII]")
return 1.0 if actual_count == expected_count else 0.0
# ===== Rubric =====
# Define Rubric
rubric = vf.Rubric(
parser=parser,
funcs=[
exact_match_reward,
pii_count_reward,
format_reward,
],
weights=[1.0, 0.5, 0.1],
)
# ===== Environment =====
# Define Environment
vf_env = vf.SingleTurnEnv(
dataset=dataset,
eval_dataset=eval_dataset,
system_prompt=system_prompt,
parser=parser,
rubric=rubric,
)
# Return Environment
return vf_env
The above code constitutes a a single turn environment, which expects a training dataset, evaluation dataset, system prompt, parser and rubric.
Full documentation on Verifiers can be viewed here!
Dataset
The dataset is loaded via HuggingFace datasets in this snippet
# ===== Dataset =====
# Load Dataset
ds_all = load_dataset("AdamLucek/open-pii-masking-en-us-30k")
dataset = ds_all["train"]
# Limit Training Examples if Specified
if num_train_examples != -1:
dataset = dataset.select(range(min(num_train_examples, len(dataset))))
# Calculate eval size
# Default to 20% of train dataset
if num_eval_examples != -1:
test_size = min(num_eval_examples, max(1, len(dataset) - 1))
else:
test_size = 0.2
# Split Dataset
split = dataset.train_test_split(test_size=test_size, seed=random_seed, shuffle=True)
# Select Training and Evaluation Datasets from Split
dataset = split["train"]
eval_dataset = split["test"]
The dataset itself is already in the expected format by Verifiers’ data loader setup:
{
"question": str, # The prompt text as a string
"answer": str, # Ground truth answer
"info": dict, # Additional metadata
"task": str # Identifier
}
So no additional transformation or mapping is required before we perform a default 20% split on the shuffled dataset to create the final train and eval splits.
Importantly, passing in a dataset with the column question then expects a system prompt to be provided as well, which we define as:
"""Replace all personally identifiable information (PII) in the text with [PII] tags.
PII includes: names, dates, phone numbers, SSNs, account numbers, addresses, email addresses, and any other identifying information.
Examples:
Input: Ticket Reservation for Florije: 'one ticket for Madame on October 8th, 1990'
Output: Ticket Reservation for [PII]: 'one ticket for [PII] on [PII]'
Input: User account recovery: "Hi Arljind Komla, your account recovery key is 426220045."
Output: User account recovery: "Hi [PII], your account recovery key is [PII]."
Return ONLY the masked text wrapped in masked_output XML tags:
<masked_output>
[Your masked text here]
</masked_output>"""
Note: It’s also possible to input a list of OpenAI chat completion formatted messages. When passing in examples via a string in the question column, Verifiers handles this formatting automatically.
Parsing
For parsing the output generated by the LLM we use another built in module, XMLParser.
XMLParser does exactly what you’d expect, given a string and defined XML fields it will parse the input into the expected sections based on the XML fields, i.e:
parser = XMLParser(fields=["reasoning", "answer"], answer_field="answer")
# Input XML text
xml_text = """
<reasoning>
Let me solve this step by step.
First, I need to calculate 2 + 2.
That equals 4.
</reasoning>
<answer>
4
</answer>
"""
result = parser.parse(xml_text)
print(result.reasoning) # Let me solve this step by step.
First, I need to calculate 2 + 2.
That equals 4.
print(result.answer) # 4
The answer_field defines which parsed section is considered the final output and propogates through to the reward functions for scoring.
As we define in our system prompt, our LLM will only output the final answer wrapped in <masked_output></masked_output>, so we can pass in masked_output as both the only field and answer field:
# ===== Parser =====
# Define Parser
parser = vf.XMLParser(fields = ["masked_output"], answer_field = "masked_output")
Rewards & Rubric
The three reward functions are all that’s left
-
Accuracy Reward
# Exact Match Reward Function def exact_match_reward(parser, completion, answer) -> float: parsed_answer = parser.parse_answer(completion) or "" return 1.0 if parsed_answer.strip() == answer.strip() else 0.0 -
Format Reward
We can use the Verifier’s parser built in .get_format_reward_func() method to return a reward function based on the input format. The built in format reward function has the following logic:
- Field presence (40%): Is
<masked_output>present? - Correct spacing (20%): Does it parse correctly with proper spacing?
- Starts with first field (20%): Does message start with
<masked_output>? - Ends with last field (20%): Does message end with
</masked_output>?
# Format Reward Function format_reward = parser.get_format_reward_func() - Field presence (40%): Is
-
Partial/Heuristic Signal
# PII Count Reward Function def pii_count_reward(parser, completion, info) -> float: parsed_answer = parser.parse_answer(completion) or "" expected_count = info.get("pii_count") actual_count = parsed_answer.count("[PII]") return 1.0 if actual_count == expected_count else 0.0
These functions are packaged with the parser and individual weightings to get our final rubric that the LLM will be scored against.
# Define Rubric
rubric = vf.Rubric(
parser=parser,
funcs=[
exact_match_reward,
pii_count_reward,
format_reward,
],
weights=[1.0, 0.5, 0.1],
)
The final reward is then calculated as:
$$ \text{reward} \;=\; 1.0 \times \texttt{exact_match_reward} \;+\; 0.5 \times \texttt{pii_count_reward} \;+\; 0.1 \times \texttt{format_reward} $$
This yields a composite score in [0, 1.6]: exact-match correctness dominates (up to 1.0), with smaller bonuses for correct PII counting (0.5) and well-formed output (0.1). Intuitively, getting an exact match matters most, while correct formatting and count provide auxiliary credit.
Environments Hub
Everything defined above is then packaged nicely into a SingleTurnEnv ready for use!
# Define Environment
vf_env = vf.SingleTurnEnv(
dataset=dataset,
eval_dataset=eval_dataset,
system_prompt=system_prompt,
parser=parser,
rubric=rubric,
)
Prime Intellect has also made it easy to publish and share environments via the Environments Hub, you can check out this specific environment at adamlucek/pii-masking. If you find yourself making an environment, definitely support their push for open source sharing and toss it over there!
Training a Model
The final step is to then apply all of this towards training a LLM within the environment. For my own experiment I opted to use Tinker, Thinking Machine Lab’s LLM fine tuning service. They’ve already provided a suite of Tinker Cookbook Recipes for Verifiers RL that make it straightforward to integrate your own Verifiers environment. Tinker natively supports reinforcement learning, more examples can be seen in the Tinker RL Documentation.
For this experiment, I opted to train Qwen/Qwen3-4B-Instruct-2507 using Tinker’s verifiers_rl script with the following arguments:
uv run python -m tinker_cookbook.recipes.verifiers_rl.train \
vf_env_id=pii-masking \
vf_env_args='{"num_train_examples": -1}' \
model_name="Qwen/Qwen3-4B-Instruct-2507" \
lora_rank=32 \
groups_per_batch=32 \
group_size=8 \
learning_rate=1e-5 \
max_tokens=512
This run contained 740 steps, ran for roughly ~5 hours, cost ~$19 and produced the following reward curve:
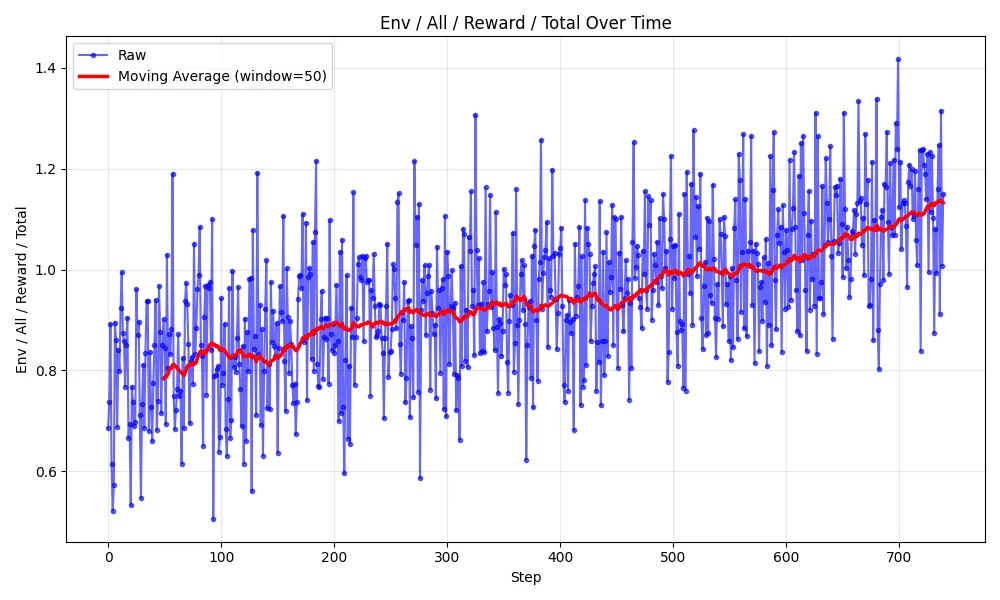
The final adapter was then merged with the base model to produce AdamLucek/Qwen3-4B-Instruct-2507-PII-RL!
Running an evaluation with 50 examples × 3 rollouts each (150 total) across the base model, the fine-tuned model, and Anthropic Sonnet 4.5 yields:
| Metric | Qwen3-4B (Base) | Qwen3-4B-PII-RL (FT) | Anthropic Sonnet 4.5 |
|---|---|---|---|
| Total Reward | 0.630 | 0.883 | 0.729 |
| Exact Match | 0.320 | 0.500 | 0.420 |
| PII Count / Accuracy | 0.420 | 0.567 | 0.420 |
| Format | 1.000 | 1.000 | 0.992 |
In this setup, Qwen3-4B-Instruct-2507-PII-RL outperforms Sonnet 4.5 on mean total reward, exact match, and PII Count, and matches/exceeds it on Format. To confirm generalization, additional experiments on held-out data need to be run, but our training definitely helped!
Takeaways
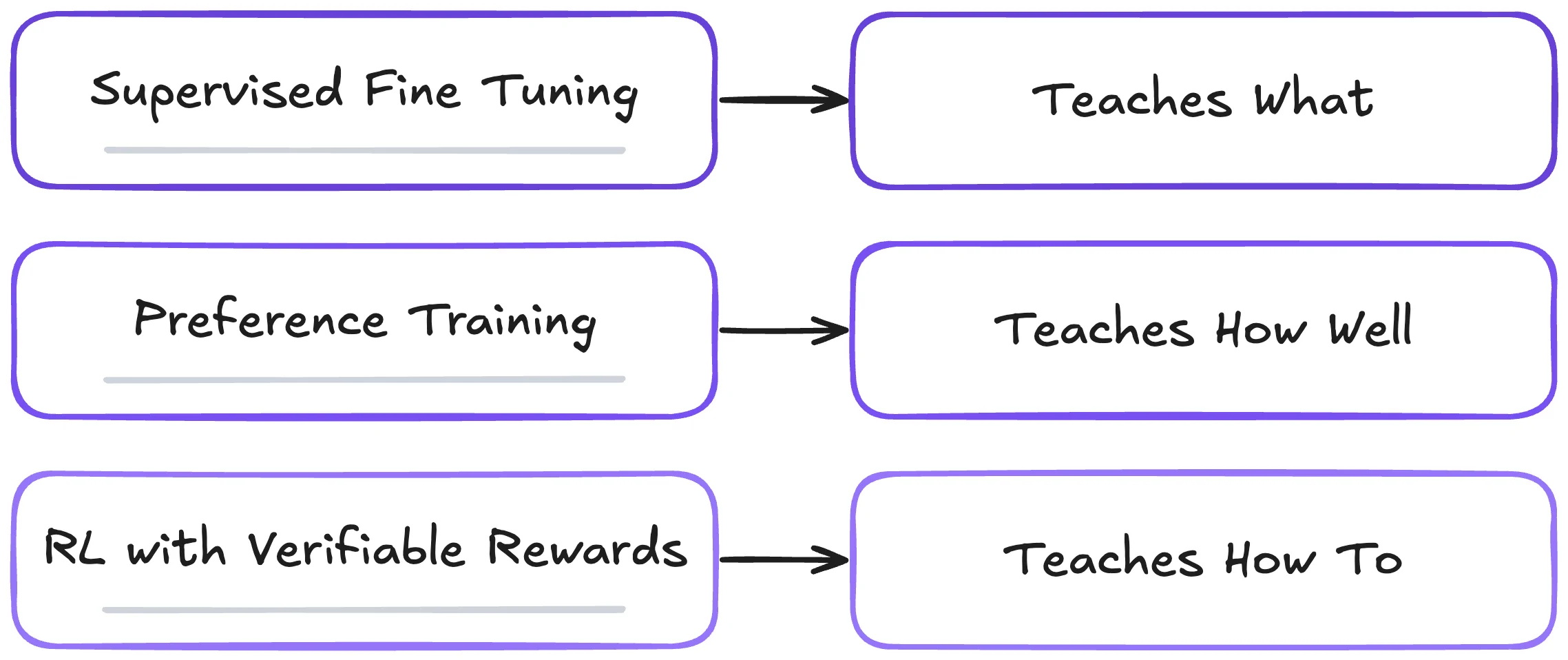
Reinforcement learning is a critical step in LLM post-training, complementing supervised fine-tuning by enabling preference training through techniques like RLHF and procedure generalization through RLVR. The field of RL using verifiable rewards has become notably popular due to its relative simplicity and the emergent benefits of training on outcomes. As a rule of thumb:
- SFT teaches “what” (formats, facts, behaviors)
- Preference training teaches “how well” (quality, style, safety)
- RLVR teaches “how to” (procedures, strategies, problem-solving)
Importantly, the “reasoning” capabilities observed in models like DeepSeek-R1 appear to be emergent byproducts of optimizing for verifiable outcomes, not explicitly trained behaviors. Models learn to construct and execute procedures that reliably achieve results.
Creating RLVR environments involves diligent prep work of defining the world, action space, and reward signals. Rewards tend to focus on binary indicators of accuracy and format on output, often scoring full sequences rather than individual segments. This technique, combined with RL algorithms, can drive improvements with even limited data.
Overall, RLVR is an exciting and promising direction for developing specialized LLM capabilities. The key is verifiability: if you can programmatically check whether a task was completed successfully, you can likely train a model to excel at it through reinforcement learning. As the field matures and tools like Verifiers become more sophisticated, we should expect to see RL-trained models tackling increasingly complex procedural tasks that were previously thought to require human-level reasoning.