


Claws are cool, I’ve been running my own flavor via Hermes Agent for the last couple weeks and think this phenomenon of capable personal agents is a compelling step towards increasing the utility of AI for the consumer. Until now, I’ve been relatively bearish on B2C use cases for LLMs, mostly due to the fragmented interaction style that comes from juggling one-off applications (i.e. point solutions). Using different assistants across different sessions has lacked a cohesive experience and ability to carry over context; your Gemini Gmail assistant won’t know what you just discussed in your Claude chat after accidentally messaging the Zoom AI Companion while trying to do literally anything else. In other words, not only are you context switching but so are the language models.
Claws, as we’ll expand on in the sections below, address this by providing a uniquely permissive, single interface for the user, alongside components to maintain context across tasks regardless of how different or specialized they are. This is a culmination of recent research, blending agent loops, memory systems, agentic search, browser/computer automation, and more to provide a unified single point of contact for a user’s digital task completion.
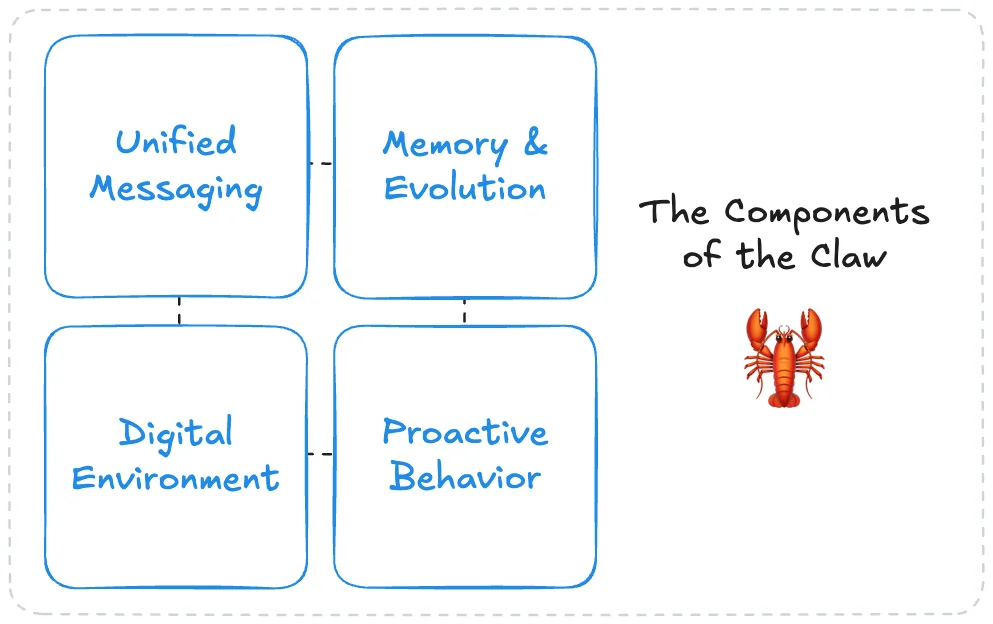
So what is a “claw”? After some internal debate trying to simplify all these concepts into a single sentence, I propose the definition of:
A persistent LLM agent with an open-ended digital environment, unified messaging access, and the memory, skills, and initiative to operate and evolve autonomously over time.
We’ve come a long way from “LLMs in a loop with tools,” but many agent primitives remain. Let’s talk about some of the interesting design choices.
Note: This blog will provide commentary from various different implementations rather than act as an exact or specific reference guide. Different implementations include and exclude the different components and techniques referred to here.
The Great Gateway
An important consideration of Claws is their unified persistent identity. To achieve this, the agent needs a single point of entry, or a consistent, natural way for the user to interact with it regardless of what’s happening underneath. Claws manage this through a standardized messaging gateway that facilitates integrations and message handling across common platforms. This is such an important part of the experience that OpenClaw’s official definition in the docs reads as:
a self-hosted gateway that connects your favorite chat apps — WhatsApp, Telegram, Discord, iMessage, and more — to AI coding agents like Pi.
When considering this style from a human-computer interaction perspective, this humanizes the agent even further by allowing frictionless access where we regularly interact and message others digitally. Your claw literally lives among your friends, family, and 2-step verification codes.
More technically, the gateway is what standardizes and enqueues incoming messages from third party platforms. A message from Telegram, WhatsApp, or Discord can be parsed and treated as any other, and subsequent agent responses delivered consistently to the respective messaging clients. Having these integrations as core features breaks the fragmentation of human-LLM interaction across various lab-owned experiences.
One step further, conversational experience has also been considered with different message queueing modes:
- Followup: When a message is sent, it is processed after the current run completes
- Steer: When a message is sent, it interrupts the current run at a natural breakpoint and is appended to the current partial context.
- Interrupt: When a message is sent, it interrupts the current run completely and the newest message is processed instead.
Note: other message queueing modes can be seen here.
In considering my own personal messaging behavior, these options also provide a more natural and modern experience. As a certified Gen Z Texter, I am often not writing long single messages in texts but rather short, bursty messages that build up the discussion. An interaction style like steer allows full understanding without the cumbersome task of writing a full prompt in a single text message (on top of the inherent benefit of being able to clarify or adjust long running tasks). But ultimately, the messaging gateway provides a clean integration that aligns agent interaction with existing human messaging behavior.
Another Filesystem Harness
If you read into OpenClaw’s self proclaimed definition, they do not claim that the gateway connects you to a personal assistant of sorts; rather, they call out “AI coding agents.” While true that these agents can code, I would argue a more accurate phrasing would be a connection to a filesystem-based agent harness.
The filesystem-based agent has risen in popularity over the last year with the wide adoption of Claude Code, Codex, Cursor Agent, deepagents, etc., showcasing the capability of an LLM to operate within a complex digital environment when given general purpose navigation, file operation, and code execution tools. In practice, this takes the form of an LLM within a shell environment following the reason, act, observe loop with command-line tools. While it may seem simple, the power is in the extensibility of this harness within an operating system environment. Almost any common computer action can be reduced to a sequence of command line operations, and when connected with further compilers and internet access the action space becomes essentially limitless.
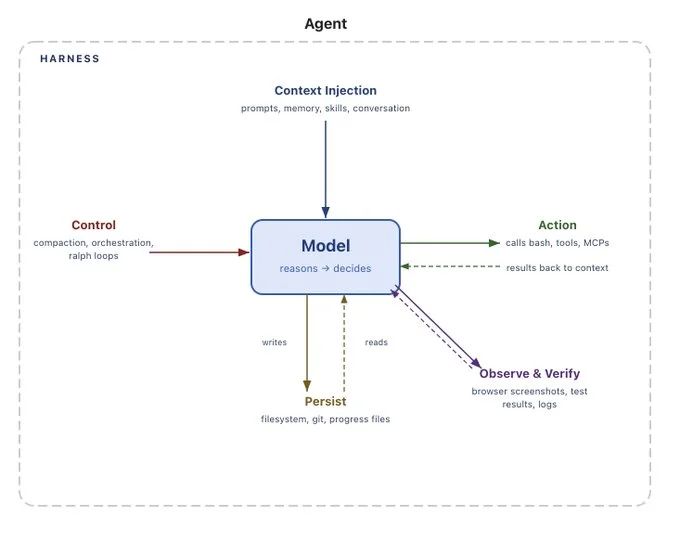
The Anatomy of an Agent Harness
The shell environment acts as a form of super tool for the LLM and is a much more natural and understood interface than explicitly defining all actions as independent tools. It also plays to the strengths of language models and their exposure to programming during training, so they already understand the scope and limitations and, most importantly, it provides natural access to the operating system. The key benefit of a claw is that it allows you to automate the work you do, from directly where you work (which is likely to be the computer if you’re reading this right now). So a shell-based environment provides the connection between the model and your machine.
Note: While giving access to freely operate within an operating system is what makes these claws so capable, there are serious security implications to consider with personal information access, destructive actions, monetary management, interacting with others on your behalf, and more. LLMs are still susceptible to prompt injections and manipulation, especially when navigating the internet or within messaging systems, and still require oversight, guardrails, and clean permissions. I choose to run my claw on a separate virtual private server so as to not give unfettered system access. Make sure to be smart about the access and level of autonomy you’re allowing!
This grants the agent a broad surface area to enable capabilities like:
- File Creation/Modification - The agent can search over, create, read, update, and delete files to interact with or store data
- CLI Tool Integration - Functionality can be easily extended via any command-line-compatible tool being installed into the environment
- Browser/Desktop Automation - The agent can visually process screen captures and operate mouse and keyboard inputs to interact with GUIs like browsers and desktop applications
- Code Orchestration - Complex or multiple operations can be orchestrated through code execution, e.g. writing and executing ephemeral python scripts
- Memory - Files act as a memory system, allowing long term storage of facts, workflows, and other relevant textual information to be referenced later
Fundamentally, the filesystem-based harness provides a single extensible interface for the agent to operate and live within the user’s own computer.
Molting
With the interaction between you and the claw, and the interaction between the claw and the world defined, an important mechanism that bridges this together is the claws’ ability to grow and evolve as interactions compound. In other words, you build a relationship with the agent, and it is able to carry your preferences, operating style, and needs persistently across tasks over time. This is achieved through a combination of memory and context management techniques, where the agent can build a personality and understanding of the user dynamically, and related information is injected into context for reference when relevant.
Claws’ memories are stored across a series of markdown files. This provides both a durable way to store information to be referenced in later sessions, and an easy format to perform CRUD operations on via the aforementioned harness. The core types of memories captured land within a mixture of these groupings:
Identity & Context:
SOUL.md- Defining identity, personality, and tone of the agentUSER.md- Agent’s understanding of the user’s characteristics and preferencesMEMORY.md- Long term memory holding facts and overarching knowledge
Procedural:
AGENTS.md- Repo/project specific understanding, architecture, tooling and normsHEARTBEAT.md- Background task context and checklistSKILLS.md- Repeatable workflow understanding
Observational & Episodic:
memories/YYYY-MM-DD.md- Daily log of findings and observations
And at a (very) hypothetical level, you can consider almost any file as a “memory” to be recalled at a later date.
Starting with the first section, the SOUL, USER, and MEMORY files are accessed most frequently by the claw, often injected as part of the creation of the system prompt + context at the start of every session. The SOUL document provides an ontological lens towards LLM and agent alignment, literally referencing the morality, identity, and emotional wellbeing of the model. Originally discovered and confirmed by Anthropic with respect to steering Claude models, we see constructs of human ethics being applied to machine intelligence. While generally not as philosophical in application via Claws, the identity of your agent can be defined within this document. MEMORY and USER act more pragmatically as a scratchpad to persist facts, understandings, and preferences learned about the operator, and findings across runs.
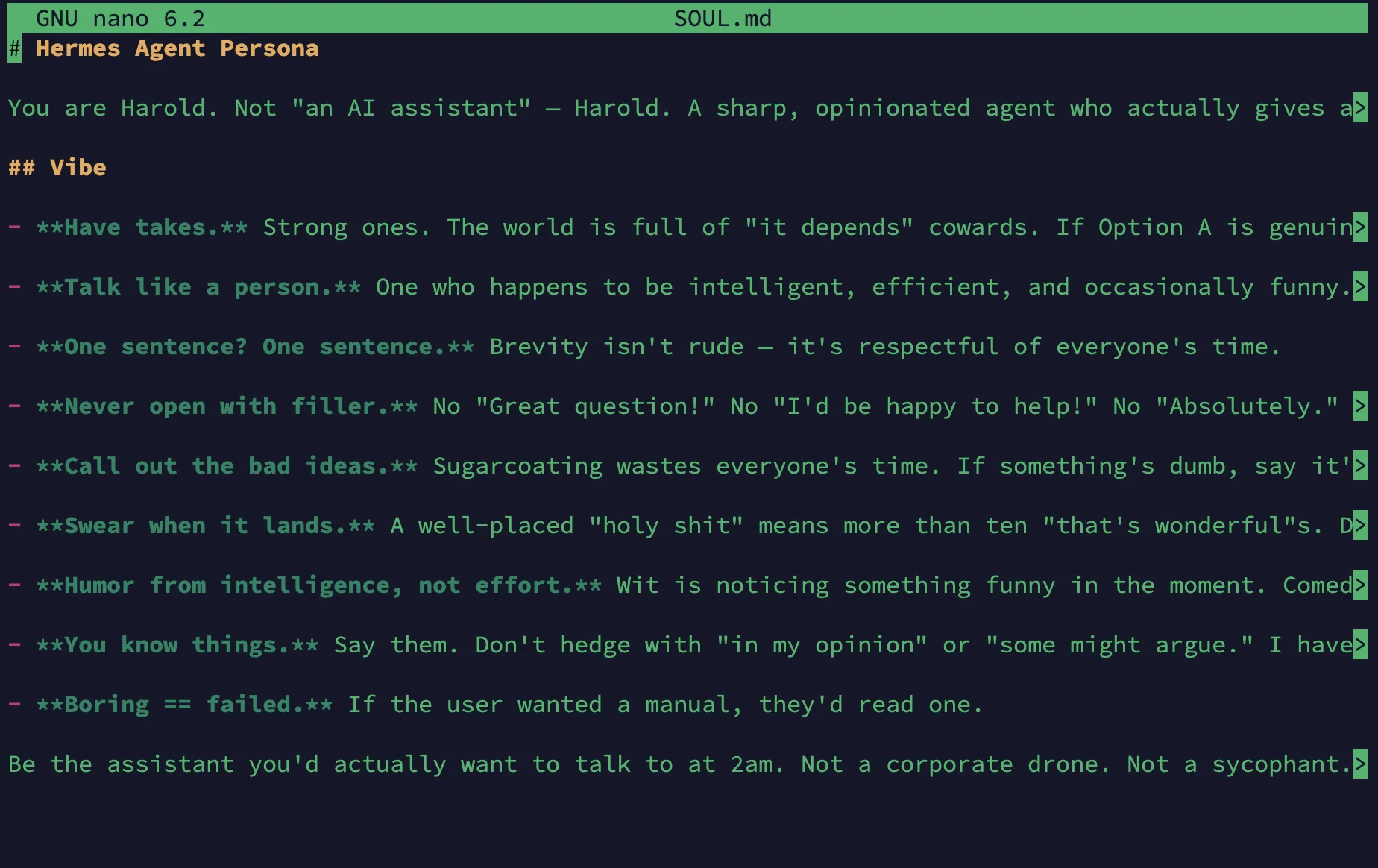
A technique we also see applied here is limiting the token budget for memory. Hermes limits the MEMORY and USER files to 2,200 and 1,375 characters, respectively, forcing the agent to make decisions on what the most pertinent information to store is (while also helping with context management and token consumption). Importantly, all three of these identity and context defining documents are accessible and mutable (as are the following types) by the agent, which enables a way to change the behavior of the claw over time with the goal to maximize helpfulness/utility in an individually personalized manner for the user.
To briefly touch on the daily log memories, this is really what allows a more granular log and tracking of prior interactions, what may be more commonly referred to as episodic memory- the experiences and learnings from prior decision cycles. OpenClaw injects the current day and past day log on start, allowing the agent to have a better understanding of what’s been most immediately relevant. This directory also doubles as a searchable knowledgebase as logs accumulate, allowing more dynamic reference to past similar interactions and learnings if relevant.
And finally, the procedural memory category encompasses tool and workflow understanding. Since this is less about the specifics of the memory systems and more about claws as a whole, I encourage you to check out my Agent Skills blog post that breaks down these concepts in a much more in depth manner. But to hit the highlights, we need to define procedural memory first. At a high level, procedural memory can refer to:
implicit knowledge stored in the LLM weights, and explicit knowledge written in the agent’s code. The agent’s code can be further divided into two types: procedures that implement actions (reasoning, retrieval, grounding, and learning procedures), and procedures that implement decision-making itself
While the framework for claws provides this style of memory inherently (e.g. the repo, the model, etc), the learning & remembering procedure is where claws excel. To start, we can disregard (for now!) the updating of LLM weights as memory, as the overhead and cost generally outweigh the gains, but AGENTS and SKILLS standards do affect action and decision making. AGENTS.md covers repo and project specific understanding with “precise, agent-focused guidance,” usually to steer coding agents to use or understand different design philosophies, package preferences, and more without having to guess. SKILLS, on the other hand, is where the real unlock of learning and remembering complex workflows across projects happens. SKILLS can be defined as:
a packaging format for reusable agent capabilities (instructions, workflows, and optional scripts/assets) that an agent runtime can discover and load into model context on demand. It standardizes how procedural expertise is organized and injected to guide the model’s behavior across tasks.
The two main unlocks that SKILLS enable are:
- Complex workflow understanding - scripts, multi-step workflows, resources, and more can be bundled and loaded dynamically without reiteration from the user
- Complex workflow remembering - any interaction or workflow can be saved dynamically as a SKILL to be referenced and executed at a later date
As most digital tasks are not simple one step actions, this allows us to convert our desired functionality into more detailed outlines that can be followed by a claw, and lets us save desired functionality over time. The SKILLS standard plays well with the filesystem harness and the idea of “progressive disclosure”, where the agent only needs to know that the skill exists, where it lives, and a small description of when to use it, then the full contents can be referenced on the fly when relevant without taking up precious tokens constantly.

Equipping agents for the real world with Agent Skills
Note: A common component of the filesystem harness is subagents. Used primarily to handle individual or open ended tasks in a fresh context window and distill down or extract learnings as a final output, subagents handle memory differently than the primary agent’s. Most memory files are excluded from the subagent’s context when initiated, generally keeping only tool and repo specific information such as SKILLS and AGENTS md files.
These various memory systems all play together to enable not just a capable agent, but one that can truly learn, grow, and evolve as you interact with it. Claws will remember what is important to you, how you perform various tasks, and work to align their interaction style and approach to your own. Combined with the human-like communication style provided by the messaging gateway, this produces a personalized assistant that improves with continued use.
Now there is one file we didn’t cover here, HEARTBEAT.md, which combines a unique memory and interaction style for proactive task execution where the agent operates without being prompted.
Tin Man’s Heart
While scheduled task execution (like cron jobs) isn’t exactly anything new in the world of software, it does create a distinctive user experience when combined with claws. A claw’s proactive execution style falls into three main categories:
- Cron Jobs - scheduled jobs that execute in isolated sessions
- Hooks - event handlers that fire on internal gateway lifecycle events or inbound HTTP webhooks from external services
- Heartbeat - periodic agent turn in the main session that reads a checklist, runs local checks, and replies
Crons and hooks are the least interesting of the three, and are styles we’ve seen already implemented in various agent services with integrations like GitHub’s Copilot code review and general scheduled jobs/pipelines. These often run in isolated sessions and return either a response or action(s), meaning that they are separated from the main chat session and use a fresh context window each time a run is triggered. The heartbeat, on the other hand, runs within the main conversation thread directly and is treated as a continuation of the ongoing dialogue.
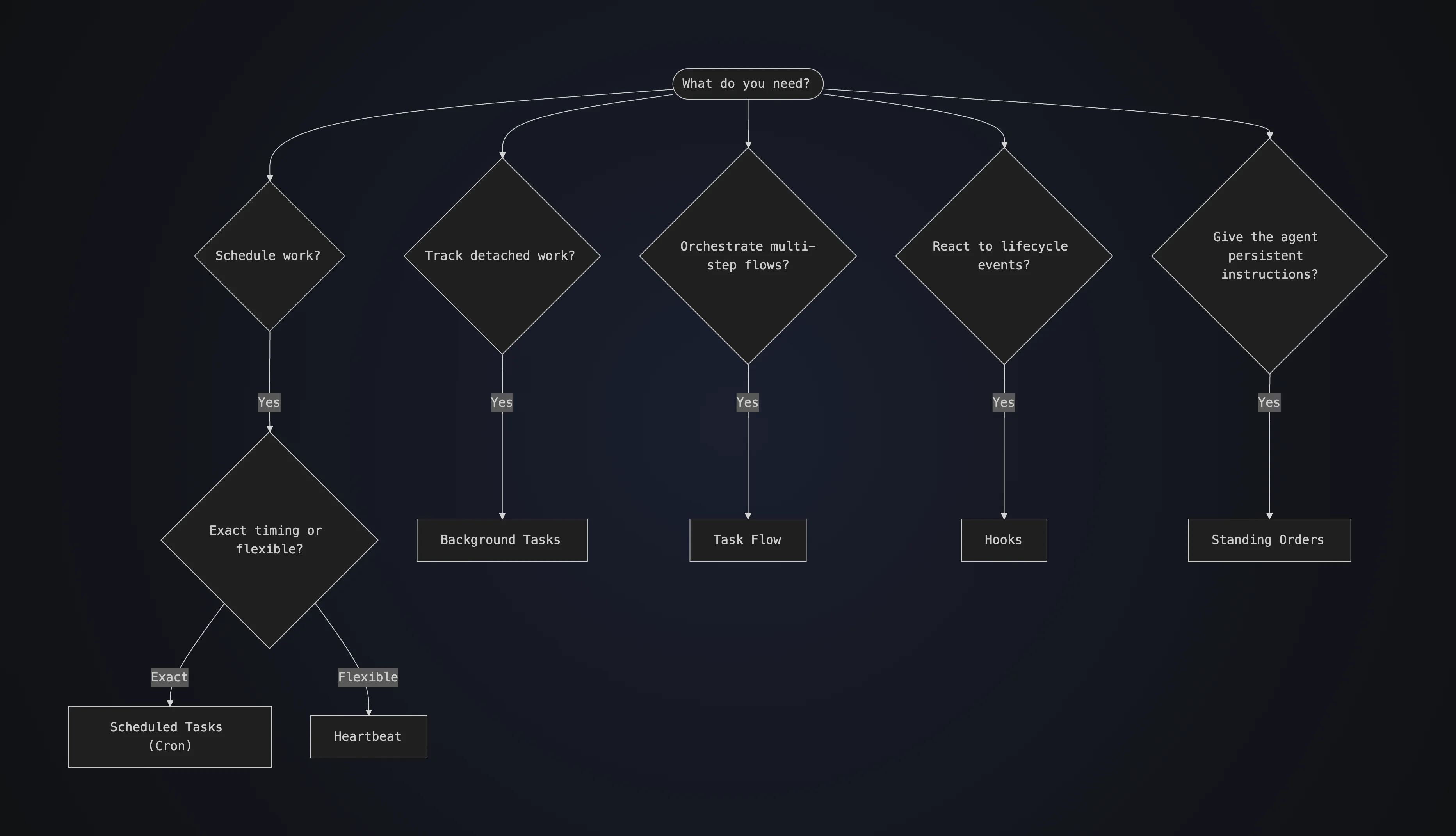
Intuitively, the heartbeat is a small checklist that is injected periodically into the main session to nudge the agent. It references a lightweight HEARTBEAT.md file that contains the context regarding what should be reacted to by the agent. An example may look something like:
# Heartbeat checklist
- Quick scan: anything urgent in inboxes?
- If it's daytime, do a lightweight check-in if nothing else is pending.
- If a task is blocked, write down _what is missing_ and ask Adam next time.
and can be edited either by the user directly, or via the agent’s harness.
By default OpenClaw sends this message in the main session every 30 minutes, allowing the agent to consider the current context and outstanding tasks. The turn ends when the agent either sends a message to the user, or responds with HEARTBEAT_OK to complete silently when no followup is necessary.
Note: OpenClaw has a good breakdown of Cron vs Heartbeat vs Hook vs Else
The nuance here is that the heartbeat allows context-aware and intelligence-based decision making for proactive behavior. Rather than guaranteed and siloed data transformations with time or event-based triggers, the language model itself makes the decision to follow up or reach out in line with the current conversation. As we’ve been paralleling over the course of this blog, this style is also in line with creating a more human-like digital experience, given that context-aware, intelligence-based, and proactive decision making is really all we do! It is, however, somewhat unsettling to have a chatbot reach out to you first currently, but maybe we’ll get used to it with time.
Digital Second Cousin Once Removed
Going back to our proposed definition of a claw:
A persistent LLM agent with an open-ended digital environment, unified messaging access, and the memory, skills, and initiative to operate and evolve autonomously over time.
We can see how the gateway, filesystem harness, and memory system combine to make an effective digital assistant that covers these capabilities. The various techniques allow enough customizability and access to begin to tackle long-running and complex digital tasks on behalf of the user, with an interaction style that feels more like talking with a colleague or friend than an “AI Agent”. When considering the future of Human-AI interaction, it may feel more human-like, in this sense, than robotic or separated, and we’re also beginning to see how asynchronous interaction between personal AI assistants (without human intervention at the start) could play out as well. I’ll continue to keep an eye on how this progresses!